ChatGPT的火爆����,直接引爆了大模型的繁榮�,也使得NVIDIA GPU供不應(yīng)求�。
從發(fā)展的角度看,GPU并不是大模型最高效的計(jì)算平臺(tái)�����。
GPT等大模型為什么沒有突破萬億參數(shù)���?核心原因在于在現(xiàn)在的GPU平臺(tái)上���,性能和成本都達(dá)到了一個(gè)極限。想持續(xù)支撐萬億以上參數(shù)的更大的模型�,需要讓性能數(shù)量級(jí)提升,以及單位算力成本數(shù)量級(jí)的下降�����。這必然需要全新架構(gòu)的AI計(jì)算平臺(tái)����。
本文拋磚引玉,期待行業(yè)更多的探討�����。
1.綜述
大模型為什么“不約而同”的停留在上千億的參數(shù)規(guī)模�����,沒有突破萬億參數(shù)�?原因主要在于,在目前的架構(gòu)體系下:
單個(gè)GPU性能增長(zhǎng)(Scale up)有限���,想要增加性能����,只有通過增加計(jì)算集群規(guī)模(Scale out)的方式����;
上萬GPU的計(jì)算集群,其東西向的流量交互指數(shù)級(jí)提升�,受限于集群的網(wǎng)絡(luò)帶寬,約束了集群節(jié)點(diǎn)計(jì)算性能的發(fā)揮�;
受阿姆達(dá)爾定律的約束,并行度無法無限擴(kuò)展��,增加集群規(guī)模的方式也到了瓶頸�����;
并且,如此大的集群規(guī)模�,成本也變得不可承受。
總的來說���,為了數(shù)量級(jí)的突破算力上限��,需要從如下幾個(gè)方面入手:
首先�,性能提升不單單是單個(gè)芯片的事情����,而是一個(gè)系統(tǒng)工程。因此��,需要從芯片軟硬件到整機(jī)再到數(shù)據(jù)中心全體系進(jìn)行協(xié)同優(yōu)化���。
其次��,擴(kuò)大集群規(guī)模��,也即大家熟知的Scale Out�����。要想Scale out�����,就需要增強(qiáng)集群的內(nèi)聯(lián)交互����,也就是要更高的帶寬�����,更高效的高性能網(wǎng)絡(luò)���。同時(shí)����,還需要降低單個(gè)計(jì)算節(jié)點(diǎn)的成本���。
最后����,最本質(zhì)的�,Scale Up����,增加單個(gè)節(jié)點(diǎn)的性能��。這個(gè)是最本質(zhì)的能夠提升算力的方法���。在功耗���、工藝、成本等因素的約束下�,要想提升性能,只能從軟硬件架構(gòu)和微架構(gòu)實(shí)現(xiàn)方面去挖潛���。
2. 全體系協(xié)同優(yōu)化
算力�����,不僅僅是微觀芯片性能的事情��,而是宏觀上復(fù)雜而龐大的系統(tǒng)工程�����。整個(gè)體系中�,從工藝到軟件,從芯片到數(shù)據(jù)中心���,整個(gè)算力體系中的各個(gè)領(lǐng)域的發(fā)展都已經(jīng)達(dá)到一個(gè)相對(duì)穩(wěn)定而成熟的階段���。而AI大模型的發(fā)展,仍然需要算力大踏步的提升��,這不僅僅需要各領(lǐng)域按部就班的持續(xù)優(yōu)化����,更需要各個(gè)領(lǐng)域間的跨域協(xié)同優(yōu)化創(chuàng)新:
半導(dǎo)體工藝和封裝:更先進(jìn)的工藝���、3D集成��,以及Chiplet封裝等���。
芯片實(shí)現(xiàn)(微架構(gòu)):通過一些創(chuàng)新的設(shè)計(jì)實(shí)現(xiàn),如存算一體�、DSA架構(gòu)設(shè)計(jì)以及各類新型存儲(chǔ)等。
系統(tǒng)架構(gòu):比如開放精簡(jiǎn)的RISC-v���,異構(gòu)計(jì)算逐漸走向超異構(gòu)計(jì)算��,以及駕馭復(fù)雜計(jì)算的軟硬件融合等���。
系統(tǒng)軟件���、框架、庫:基礎(chǔ)的如OS�����、Hypervisor�、容器,以及需要持續(xù)優(yōu)化和開源開放的各類計(jì)算框架和庫等���。
業(yè)務(wù)應(yīng)用(算法):業(yè)務(wù)場(chǎng)景算法優(yōu)化���、算法的并行性優(yōu)化等;以及系統(tǒng)的靈活性和可編程性設(shè)計(jì)����;系統(tǒng)的控制和管理、系統(tǒng)的擴(kuò)展性等�。
硬件,包括服務(wù)器、交換機(jī)等:多個(gè)功能芯片的板卡集成����,定制板卡和服務(wù)器,服務(wù)器電源和散熱優(yōu)化�����;
數(shù)據(jù)中心基礎(chǔ)設(shè)施:如綠色數(shù)據(jù)中心����,液冷、PUE優(yōu)化等����;
數(shù)據(jù)中心運(yùn)營和管理:如超大規(guī)模數(shù)據(jù)中心運(yùn)營管理�����,跨數(shù)據(jù)中心運(yùn)營和管理調(diào)度等����。
3.Scale out:增加集群規(guī)模
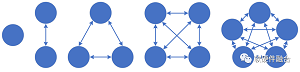
N個(gè)節(jié)點(diǎn)通過連線兩兩相連,總共的連線數(shù)據(jù)需要N*(N-1)/2���。據(jù)此公式�,集群如果只有一個(gè)節(jié)點(diǎn),那就沒有東西向的內(nèi)部流量���;隨著集群中節(jié)點(diǎn)數(shù)量的增多���,內(nèi)部交互數(shù)量會(huì)飛速的增長(zhǎng),隨之而來的����,也就是集群內(nèi)部的交互流量猛增。
據(jù)統(tǒng)計(jì)����,目前在大型數(shù)據(jù)中心中的東西向網(wǎng)絡(luò)流量占比超過85%;AI大模型訓(xùn)練集群����,其節(jié)點(diǎn)數(shù)量基本上超過1000,其東西向流量估計(jì)超過90%��。理論上����,在各個(gè)連接流量均等的情況下,目前主流網(wǎng)卡200Gbps的帶寬,即使所有都是東西向流量�,每?jī)蓚€(gè)節(jié)點(diǎn)之間的流量也僅僅只能有200/1000 = 0.2 Gbps。一方面�,南北向的流量被極限壓縮,單個(gè)連接的東西向流量又隨著集群數(shù)量的增長(zhǎng)反而持續(xù)下降����,這進(jìn)一步凸顯了網(wǎng)絡(luò)帶寬瓶頸的問題。
與此同時(shí)��,受阿姆達(dá)爾定律的影響�����,整體算力并不是跟節(jié)點(diǎn)數(shù)量呈理想的線性關(guān)系�,而是隨著集群規(guī)模的增加,整體算力的增加會(huì)逐漸趨緩�。
要想通過Scale Out方式提升集群的算力:
首先就是要快速的提升網(wǎng)絡(luò)帶寬。
其次�����,要有更優(yōu)的高性能網(wǎng)絡(luò)支持�����。通過高性能網(wǎng)絡(luò)功能優(yōu)化���,如在擁塞控制�、多路徑負(fù)載均衡ECMP�、亂序交付、高可擴(kuò)展性�����、故障快速恢復(fù)����、Incast優(yōu)化等方面進(jìn)行調(diào)優(yōu),實(shí)現(xiàn)更優(yōu)的高性能網(wǎng)絡(luò)能力��。
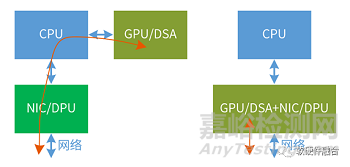
再次���,AI計(jì)算數(shù)據(jù)到網(wǎng)絡(luò)的更快速的路徑����。傳統(tǒng)架構(gòu)����,GPU作為加速卡掛載CPU外面��,從GPU到網(wǎng)絡(luò)的數(shù)據(jù)傳輸路徑非常長(zhǎng)�,并且CPU要參與傳輸?shù)目刂?����?����?梢酝ㄟ^例如GPU集成RoCE高性能網(wǎng)卡的方式��,繞過CPU���、DPU/NIC直接把數(shù)據(jù)傳輸出去���。
最后,是要從算法和軟件處層次���,提升并行度����,并盡可能的降低并行程序之間的耦合度�����。
4.Scale Up:增加單芯片性能
東西向流量本質(zhì)上屬于內(nèi)部“損耗”�,通過Scale Out的方式提升性能對(duì)網(wǎng)絡(luò)的壓力巨大,并且有性能上限��,屬于“治標(biāo)不治本”的方式�����。
要想真正的大規(guī)模的提升算力�,最本質(zhì)最有效的辦法,還是要通過提升單個(gè)計(jì)算節(jié)點(diǎn)�、單個(gè)計(jì)算芯片性能的方式。
要想提升單芯片性能:
首先���,是提升芯片規(guī)模��。通過工藝進(jìn)步�����、3D和Chiplet封裝���,提升單個(gè)芯片的設(shè)計(jì)規(guī)模���。目前,主流的大芯片晶體管數(shù)量在500億���。Intel計(jì)劃到2030年�,會(huì)將單芯片晶體管數(shù)量提高到1萬億(提升20倍)�。
第二,提升單位晶體管資源的性能效率���。6個(gè)主要的處理器類型:CPU��、協(xié)處理器�、GPU�、FPGA、DSA和ASIC�,CPU最通用,但性能效率最低��,而ASIC最專用����,性能效率最高。在計(jì)算處理器方面�,要盡可能選擇ASIC或接近ASIC的計(jì)算引擎���,盡可能的提升此類處理器在整個(gè)系統(tǒng)中的計(jì)算量占比�����。
第三���,提升通用靈活性�。性能和靈活性是一對(duì)矛盾�����,為什么不能在一個(gè)芯片里��,完全100%的采用ASIC級(jí)別的計(jì)算引擎���?原因在于����,純粹的ASIC沒有意義�。芯片需要得到大范圍的使用,才能攤薄研發(fā)成本�����。這就需要考慮芯片的通用靈活性。
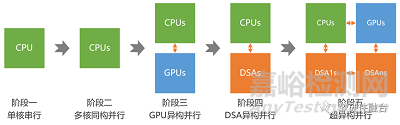
目前��,受AI等各類大算力場(chǎng)景的驅(qū)動(dòng)��,異構(gòu)計(jì)算已經(jīng)成為計(jì)算架構(gòu)的主流�。未來,隨著大模型等更高算力需求場(chǎng)景的進(jìn)一步發(fā)展�,計(jì)算架構(gòu)需要從異構(gòu)計(jì)算進(jìn)一步走向超異構(gòu)計(jì)算:
第一階段,單CPU的串行計(jì)算�����;
第二階段����,多CPU的同構(gòu)并行計(jì)算;
第三階段���,CPU+GPU的異構(gòu)并行計(jì)算�����;
第四階段�,CPU+DSA的異構(gòu)并行計(jì)算;
第五階段����,多種異構(gòu)融合的超異構(gòu)并行計(jì)算。
5.大算力芯片的通用性分析
到目前為止�,谷歌TPU都難言成功:雖然TPU可以做到�,從芯片到框架,甚至到AI應(yīng)用����,谷歌可以做到全棧優(yōu)化,但TPU仍然無法做到更大規(guī)模的落地����,并且拖累了上層AI業(yè)務(wù)的發(fā)展。原因其實(shí)很簡(jiǎn)單:
當(dāng)上層的業(yè)務(wù)邏輯和算法一直處于快速迭代的時(shí)候���,是很難把它固化成電路來進(jìn)行加速的���。
雖然谷歌發(fā)明了Transformer,但受限于其底層芯片TPU���,使得上層業(yè)務(wù)需要考慮跟底層芯片的兼容���,無法全身心投入到模型開發(fā)����;
AI模型的發(fā)展�����,目前仍在“煉丹”的發(fā)展階段�����,誰能快速試錯(cuò)快速迭代����,誰就最有可能成功。
也因此����,在AI大模型的發(fā)展進(jìn)程中,谷歌落后了�����。而OpenAI沒有包袱,可以選擇最優(yōu)的計(jì)算平臺(tái)(通用的GPU+CUDA平臺(tái))��,全身心專注到自己模型的研發(fā)���,率先實(shí)現(xiàn)了ChatGPT及GPT4這樣的高質(zhì)量AI大模型���,從而引領(lǐng)了AGI的大爆發(fā)時(shí)代。
結(jié)論:在目前AI算法快速演進(jìn)的今天��,通用性比性能重要���。也因此,NVIDIA GPU通過在GPU中集成CUDA core和Tensor Core��,既兼顧了通用性�,又兼顧了靈活性,成為目前最佳的AI計(jì)算平臺(tái)�����。
6.相關(guān)趨勢(shì)案例
6.1 Intel Hawana GAUDI

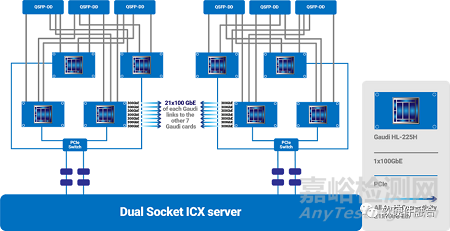
Gaudi是一個(gè)典型的Tensor加速器�。從第一代Gaudi的16nm工藝提升到第二代的7nm工藝,Gaudi2將訓(xùn)練和推理性能提升到一個(gè)全新的水平���。它將AI定制Tensor處理器核心的數(shù)量從8個(gè)增加到24個(gè)�,增加了對(duì)FP8的支持,并集成了一個(gè)媒體處理引擎�,用于處理壓縮媒體,以卸載主機(jī)子系統(tǒng)���。Gaudi2的封裝內(nèi)存在每秒2.45 Tbps的帶寬下增加了三倍����,達(dá)到96GB的HBM2e����。
Gaudi可以通過24個(gè)100Gbps的RDMA高性能網(wǎng)卡實(shí)現(xiàn)非常高的集群擴(kuò)展能力。實(shí)際的集群架構(gòu)設(shè)計(jì)�,可以根據(jù)具體的需求靈活設(shè)計(jì)。
相比傳統(tǒng)的GPU��、TPU等加速器�����,Gaudi的最大亮點(diǎn)在于集成了超高帶寬的高性能網(wǎng)絡(luò)����。從而提升了集群節(jié)點(diǎn)間的東西向流量交互效率���,也使得更大規(guī)模的集群設(shè)計(jì)成為可能。
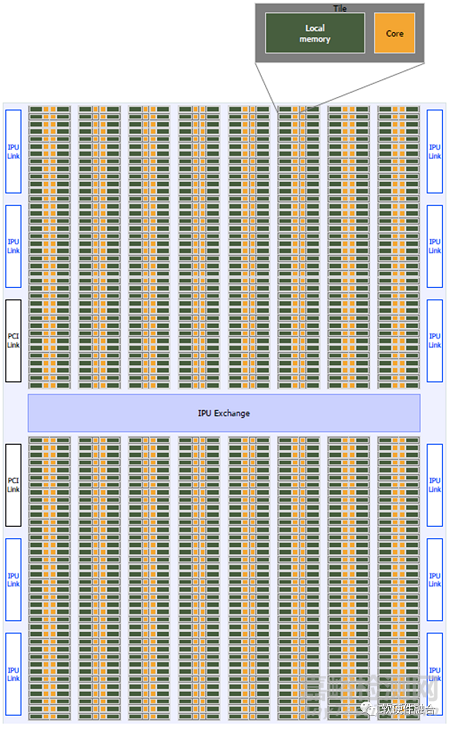
6.2 Graphcore IPU
上圖為Graphcore的IPU處理器����,IPU處理器具有1216個(gè)Tile(每個(gè)Tile包含一個(gè)Core和它的本地內(nèi)存),交換結(jié)構(gòu)(一個(gè)片內(nèi)互連)���,IPU鏈路接口用于連接到其他IPU����,PCIe接口用于與主機(jī)連接���。
Graphcore在架構(gòu)上是類似NVIDIA GPU的產(chǎn)品,是相對(duì)通用的計(jì)算架構(gòu)��,比較符合AI計(jì)算的要求�。但受限于沒有類似Tensor core這樣的協(xié)處理優(yōu)化,在性能上存在劣勢(shì)����;以及還沒有形成類似NVIDIA CUDA這樣強(qiáng)大的開發(fā)框架和豐富生態(tài)。
6.3 Tesla DOJO

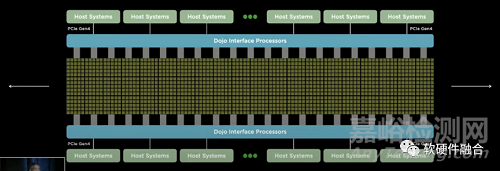
Tesla Dojo芯片和相應(yīng)的整個(gè)集群系統(tǒng)���,跟傳統(tǒng)的設(shè)計(jì)理念有很大的不同����。其基于整個(gè)POD級(jí)的超強(qiáng)的擴(kuò)展性和全系統(tǒng)棧協(xié)同設(shè)計(jì)能力。Dojo系統(tǒng)的每個(gè)Node都是完全對(duì)稱的�,是一個(gè)POD級(jí)完全UMA的架構(gòu)?��;蛘哒f��,Dojo的擴(kuò)展性��,跨過了芯片�����、Tile����、Cabinet���,達(dá)到了POD級(jí)別���。
DOJO是Tesla專用于數(shù)據(jù)中心AI訓(xùn)練的芯片�、集群和解決方案���。DOJO的可擴(kuò)展性能力����,使得AI工程師可以專注在模型開發(fā)和訓(xùn)練本身�,而較少考慮模型的分割和交互等跟硬件特性相關(guān)的細(xì)節(jié)。
DOJO也是比較通用的計(jì)算架構(gòu):內(nèi)核是一個(gè)CPU+AI協(xié)處理器的做法�����,然后多核心組成芯片��,芯片再組織成POD����。宏觀上,跟NVIDIA GPU的整體思路接近���。
6.4 Tenstorrent Grayskull & Wormhole
Tesla Dojo和Tenstorrent的AI系列芯片都是Jim Keller主導(dǎo)的項(xiàng)目,架構(gòu)設(shè)計(jì)理念有很多相似之處�。
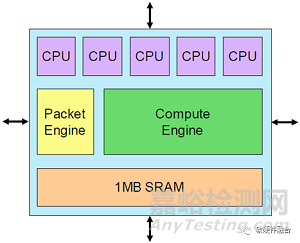
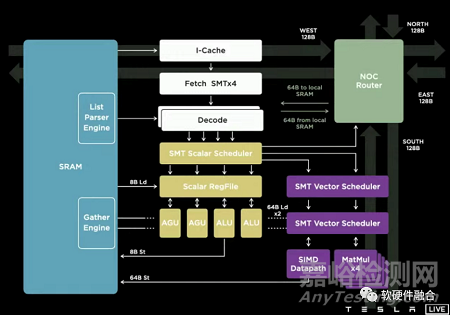
基本架構(gòu)單元是Tensix核心,它圍繞一個(gè)大型計(jì)算引擎構(gòu)建���,該引擎從單個(gè)密集數(shù)學(xué)單元承擔(dān)3 TOPS計(jì)算的絕大部分���。
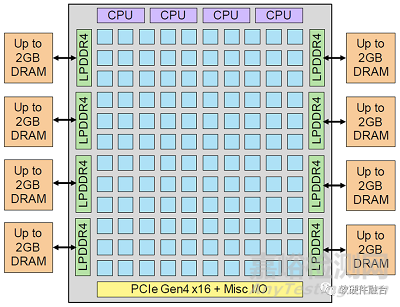
Tenstorrent的Grayskull加速器芯片實(shí)現(xiàn)了一個(gè)由Tensix內(nèi)核組成12x10陣列���,峰值性能為368 INT8 TOPS。
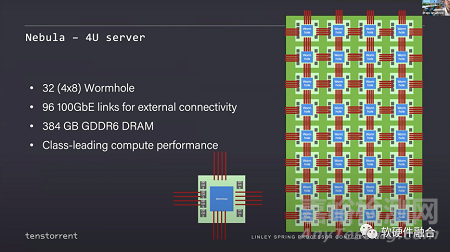
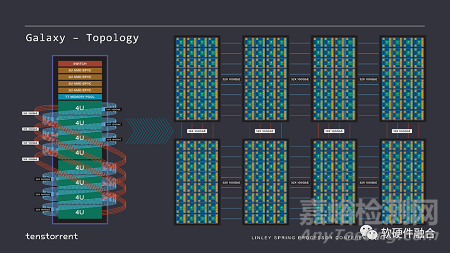
Tenstorrent的第一代芯片代號(hào)是Grayskull���,第二代芯片代號(hào)是Wormhole��,兩者宏觀架構(gòu)接近���。使用Wormhole模塊,Tenstorrent設(shè)計(jì)了nebula(星云)����,一個(gè)4U服務(wù)器包含32個(gè)Wormhole芯片。
這是一個(gè)完整的48U的機(jī)架���,它像一個(gè)2D網(wǎng)格一樣��,每個(gè)Wormhole服務(wù)器連接在另一個(gè)服務(wù)器的對(duì)等端����,就像一個(gè)大而均勻的Mesh網(wǎng)絡(luò)。
Tenstorrent通過這種多網(wǎng)絡(luò)連接的方式�����,實(shí)現(xiàn)了集群的極致擴(kuò)展性����。其整體思路和Tesla DOJO類似。