在今日舉辦的第四屆中國(guó)計(jì)算機(jī)學(xué)會(huì)集成電路與自動(dòng)化學(xué)術(shù)會(huì)議(CCF DAC)上�����,一份名為《集成芯片與芯粒技術(shù)白皮書(shū)(2023版)》的白皮書(shū)重磅發(fā)布�。劉明院士和孫凝暉院士等國(guó)內(nèi)多位集成芯片和芯粒領(lǐng)域?qū)<覅⑴c了討論和編寫(xiě)���。這份白皮書(shū)不僅剖析了集成芯片和芯粒領(lǐng)域的重要技術(shù)�����,而且包含了本領(lǐng)域的趨勢(shì)判斷分析�,為我國(guó)集成芯片與芯粒領(lǐng)域的技術(shù)攻關(guān)和發(fā)展規(guī)劃提供了重要參考。
說(shuō) 明:本白皮書(shū)基于“集成芯片前沿技術(shù)科學(xué)基礎(chǔ)”專家組組織的多次討論內(nèi)容�����,由秘書(shū)組全體成員共同整理和編寫(xiě)而成�。在編寫(xiě)過(guò)程中,為了更全面地呈現(xiàn)本領(lǐng)域相關(guān)技術(shù)���,編寫(xiě)組增加了部分技術(shù)調(diào)研內(nèi)容和趨勢(shì)判斷分析�����。集成芯片作為一個(gè)新興領(lǐng)域�,其涉及的概念和技術(shù)仍處于不斷發(fā)展之中�����,我們也意識(shí)到本白皮書(shū)中可能存在內(nèi)容闡述不夠充分�、不夠系統(tǒng)的問(wèn)題���,也誠(chéng)懇歡迎提出寶貴建議�。
1�、 前 言
1.1 背景
集成電路是現(xiàn)代信息技術(shù)的產(chǎn)業(yè)核心和基礎(chǔ)���。隨著信息技術(shù)的不斷發(fā)展�,人工智能���、自動(dòng)駕駛�、云計(jì)算等應(yīng)用通常要分析和處理海量數(shù)據(jù),這對(duì)計(jì)算裝置的算力提出了全新的要求�。例如�����,在人工智能領(lǐng)域�,人工智能大模型的算力需求在以每 3-4 個(gè)月翻倍的速度增長(zhǎng)。然而���,集成電路設(shè)計(jì)遇到“功耗墻”���、“存儲(chǔ)墻”�����、“面積墻”���,傳統(tǒng)集成電路尺寸微縮的技術(shù)途徑難以推動(dòng)算力持續(xù)增長(zhǎng)�����。另一方面�,在“萬(wàn)物智能”和“萬(wàn)物互聯(lián)”的背景下���,產(chǎn)業(yè)應(yīng)用呈現(xiàn)出“碎片化”特點(diǎn)�,需要探索新的芯片與系統(tǒng)的設(shè)計(jì)方法學(xué),滿足應(yīng)用對(duì)芯片敏捷設(shè)計(jì)的要求���。
在這樣的背景下�,需要一種新的技術(shù)途徑,可以進(jìn)一步突破芯片算力極限���、降低芯片設(shè)計(jì)復(fù)雜度。集成芯片是芯粒級(jí)半導(dǎo)體制造集成技術(shù),通過(guò)半導(dǎo)體技術(shù)將若干芯粒集成在一起�,形成新的高性能�����、功能豐富的芯片�����。通過(guò)芯粒的復(fù)用和組合,可快速滿足多種多樣的應(yīng)用需求���,帶來(lái)芯片設(shè)計(jì)、制造���、下游需求等全產(chǎn)業(yè)鏈的變革�。
對(duì)于我國(guó)而言�����,集成芯片技術(shù)對(duì)于集成電路產(chǎn)業(yè)具有更加重要意義。由于我國(guó)在集成電路產(chǎn)業(yè)的一些先進(jìn)裝備、材料、EDA 以及成套工藝等方面被限制���,導(dǎo)致我國(guó)短期內(nèi)難以持續(xù)發(fā)展尺寸微縮的技術(shù)路線�����。集成芯片技術(shù)提供了一條利用自主集成電路工藝研制跨越 1-2 個(gè)工藝節(jié)點(diǎn)性能的高端芯片技術(shù)路線�。同時(shí),我國(guó)集成電路產(chǎn)業(yè)具有龐大市場(chǎng)規(guī)模優(yōu)勢(shì)���,基于現(xiàn)有工藝制程發(fā)展集成芯片技術(shù)可以滿足中短期的基本需求���,并可借助大規(guī)模的市場(chǎng)需求刺激集成芯片技術(shù)的快速進(jìn)步,走出我國(guó)集成電路產(chǎn)業(yè)發(fā)展特色���,并帶動(dòng)尺寸微縮路徑和新原理器件路徑的共同發(fā)展。
本技術(shù)白皮書(shū)邀請(qǐng)了集成芯片與芯粒領(lǐng)域的優(yōu)勢(shì)研究力量���,詳實(shí)分析了集成芯片的技術(shù)途徑和國(guó)內(nèi)外發(fā)展現(xiàn)狀�����,總結(jié)了我國(guó)在集成芯片領(lǐng)域的基礎(chǔ)優(yōu)勢(shì)和面臨的挑戰(zhàn)���,希望能夠?yàn)榧夹g(shù)規(guī)劃�����、技術(shù)攻關(guān)、產(chǎn)業(yè)政策等提供參考�����。在撰寫(xiě)過(guò)程中�,有很多未盡之處和編委們的知識(shí)所限���,也請(qǐng)批評(píng)指正���。
1.2 本白皮書(shū)意義
本白皮書(shū)闡述了集成芯片與芯粒的內(nèi)涵�����、集成芯片架構(gòu)與電路設(shè)計(jì)技術(shù)�����、集成芯片 EDA 和多物理場(chǎng)仿真技術(shù)�����、集成芯片的工藝原理�,最后介紹了集成芯片的設(shè)計(jì)挑戰(zhàn)與機(jī)遇�。具體結(jié)構(gòu)如下:
第一章介紹了發(fā)展集成芯片和芯粒的重要意義以及本技術(shù)白皮書(shū)的內(nèi)容�����。
第二章概述了集成芯片與芯粒的內(nèi)涵���。
第三章分析了集成芯片架構(gòu)與電路設(shè)計(jì)技術(shù)�,詳細(xì)闡述集成芯片設(shè)計(jì)方法�����、多芯粒并行架構(gòu)�、芯 ?����;ミB接口協(xié)議以及芯粒間高速接口電路等關(guān)鍵技術(shù)�����。
第四章分析了集成芯片 EDA 和多物理場(chǎng)仿真的相關(guān)技術(shù)�����,包括集成芯片布局布線 EDA�、芯粒尺 度的電 - 熱 - 力多場(chǎng)耦合仿真以及集成芯片的可測(cè)性與測(cè)試技術(shù)。
第五章分析了集成芯片的工藝原理���,包括 RDL/ 硅基板(Interposer)制造工藝、高密度凸點(diǎn)鍵 合和集成工藝�����、基于半導(dǎo)體精密制造的散熱工藝等�����。
第六章討論了集成芯片的設(shè)計(jì)挑戰(zhàn)與機(jī)遇���,為未來(lái)集成芯片的發(fā)展提供參考路徑�����。
在高性能芯片發(fā)展受制的背景下�����,從我國(guó)的產(chǎn)業(yè)現(xiàn)狀出發(fā)�����,發(fā)展集成芯片——這條不單純依賴尺寸微縮的新路徑,是我國(guó)集成電路領(lǐng)域的重要的發(fā)展方向���。本白皮書(shū)希望學(xué)術(shù)界和產(chǎn)業(yè)界更廣泛而深入地了解集成芯片和芯粒技術(shù)�����,共同推進(jìn)集成芯片技術(shù)蓬勃發(fā)展�����。
2、集成芯片的內(nèi)涵
2.1 集成芯片與芯粒的定義
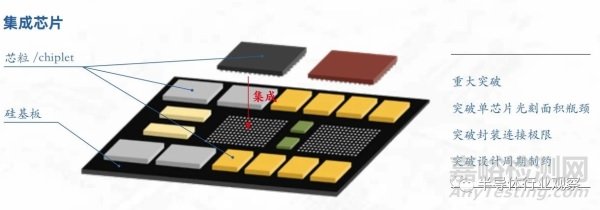
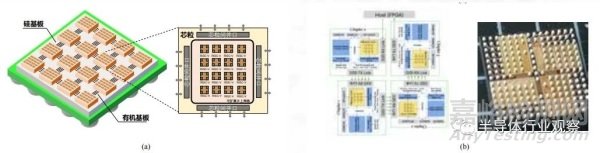
傳統(tǒng)集成電路是通過(guò)將大量晶體管集成制造在一個(gè)硅襯底的二維平面上形成的芯片�。集成芯片是指先將晶體管集成制造為特定功能的芯粒(Chiplet)���,再按照應(yīng)用需求將芯粒通過(guò)半導(dǎo)體技術(shù)集成制造為芯片�����。其中�,芯粒(Chiplet)是指預(yù)先制造好�����、具有特定功能���、可組合集成的晶片(Die)���,也有稱為“小芯片”,其功能可包括通用處理器、存儲(chǔ)器�����、圖形處理器�����、加密引擎�����、網(wǎng)絡(luò)接口等 [1]-[10]�����。硅基板(Silicon Interposer)���,是指在集成芯片中位于芯粒和封裝基板(Substrate)之間連接多個(gè)芯粒且基于硅工藝制造的載體,也有稱為“硅轉(zhuǎn)接板”�����、“中介層”�。硅基板通常包含多層、高密度互連線網(wǎng)絡(luò)�����、硅通孔 (Through Silicon Via, TSV) 和微凸點(diǎn) (Micro Bump)�����,保證了電源�、數(shù)據(jù)信號(hào)在芯粒之間和封裝內(nèi)外的傳輸,而且可以集成電容���、電感等無(wú)源元件和晶體管等有源電路�。
圖 2.1 集成芯片與芯粒的定義
集成芯片的概念源于 2010 年臺(tái)積電的蔣尚義博士提出的“先進(jìn)封裝”概念,他提出可以通過(guò)半導(dǎo)體互連技術(shù)連接兩顆芯片�����,從而解決單芯片制造的面積上限�,解決板級(jí)連接的帶寬極限問(wèn)題�����。而后���,時(shí)任美國(guó)美滿電子公司總裁的周秀文博士(Sehat Sutrardja)將“模塊化”設(shè)計(jì)思想與方法進(jìn)一步融入�����。經(jīng)過(guò)多年學(xué)術(shù)界和企業(yè)的發(fā)展,“先進(jìn)封裝”已無(wú)法涵蓋多芯粒集成后所形成的新系統(tǒng)的科學(xué)與技術(shù)�����,于是在 2022 年自然科學(xué)基金委召開(kāi)的雙清論壇上�����,孫凝暉院士�����、劉明院士以及蔣尚義先生等我國(guó)學(xué)者在凝練相關(guān)基礎(chǔ)技術(shù)后提出“集成芯片(Integrated Chips)”這一概念替代“先進(jìn)封裝”、“芯粒”等稱謂���,用于表達(dá)其在體系結(jié)構(gòu)�、設(shè)計(jì)方法學(xué)�、數(shù)理基礎(chǔ)理論、工程材料制造等領(lǐng)域中更豐富的含義���。
集成芯片設(shè)計(jì)對(duì)比傳統(tǒng)的集成電路單芯片設(shè)計(jì)可實(shí)現(xiàn)如下突破:
首先���,它可實(shí)現(xiàn)更大的芯片尺寸�����,突破目前的制造面積局限,推動(dòng)芯片集成度和算力持續(xù)提升�����;其次�����,它通過(guò)引入半導(dǎo)體制造工藝技術(shù)�,突破傳統(tǒng)封裝的互連帶寬�����、封裝瓶頸�;最后�,它通過(guò)芯粒級(jí)的 IP 復(fù)用 / 芯粒預(yù)制組合���,突破規(guī)模爆炸下的設(shè)計(jì)周期制約�,實(shí)現(xiàn)芯片的敏捷設(shè)計(jì)。
除了上述技術(shù)突破外�,集成芯片還能獲得成本上的收益���。傳統(tǒng)的單一芯片制造尺寸越大���,制造過(guò)程中的缺陷率和成本越高�。而芯粒技術(shù)允許將一個(gè)大尺寸的芯片拆分為多個(gè)小尺寸的芯粒�����,每個(gè)芯粒獨(dú)立進(jìn)行制造。由于芯粒尺寸相對(duì)較小,可以更好地控制制造過(guò)程,減少制造缺陷率和成本���。另外�����,不同芯粒可用不同的工藝制程完成�,突破單一工藝的局限。例如�����,可以將傳統(tǒng)的電子芯片與光電子器件集成在同一芯片上�,實(shí)現(xiàn)光電混合芯片���。這種光電混合芯片結(jié)合了電子和光子的優(yōu)勢(shì)�����,可以在高速數(shù)據(jù)傳輸�、光通信、光計(jì)算等領(lǐng)域發(fā)揮重要作用。上述技術(shù)也能夠?qū)崿F(xiàn)更多種類的新型芯片。例如,集成傳感器�、處理器���、無(wú)線通信模塊和人工智能加速器等多種功能���,可以構(gòu)建出具備感知-存儲(chǔ)-計(jì)算通信 - 控制一體的智能芯片�。
在集成芯片發(fā)展過(guò)程中�����,有一些并行發(fā)展的概念。集成芯片和封裝���、微系統(tǒng)主要區(qū)別在于設(shè)計(jì)方法與制造技術(shù)���。集成芯片是自上而下的構(gòu)造設(shè)計(jì)方法�����,芯粒的功能是由應(yīng)用分解得到的�����,而不是基于現(xiàn)有模組�、通過(guò)堆疊設(shè)計(jì)方法實(shí)現(xiàn)性能和功能的擴(kuò)展���。集成芯片基于半導(dǎo)體制造技術(shù)實(shí)現(xiàn)集成�����,無(wú)論連接和延遲�,都接近于芯片而不是 PCB 或者有機(jī)基板�����,因此最早做集成芯片工作的是臺(tái)積電等芯片制造廠商�。另外,我國(guó)科學(xué)家也提出了晶上系統(tǒng)[13] 和集成系統(tǒng) [14] 等概念�,在技術(shù)理念上與集成芯片有很多類似之處,相比而言�,集成芯片更側(cè)重于綜合性和面向芯片形態(tài)。
2.2 集成芯片是集成電路性能提升的三條路徑
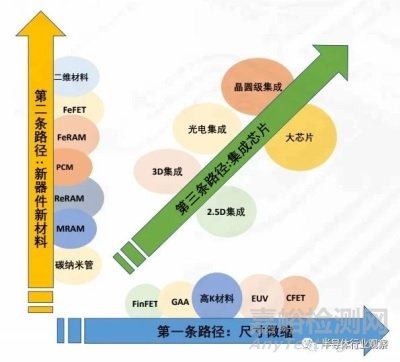
從技術(shù)上看���,目前主要有三條提升芯片性能的發(fā)展路徑���,如圖 2.2 所示,三條技術(shù)路徑從不同維度共同推動(dòng)集成電路的發(fā)展�����。
圖 2.2 提升芯片性能的三條路徑
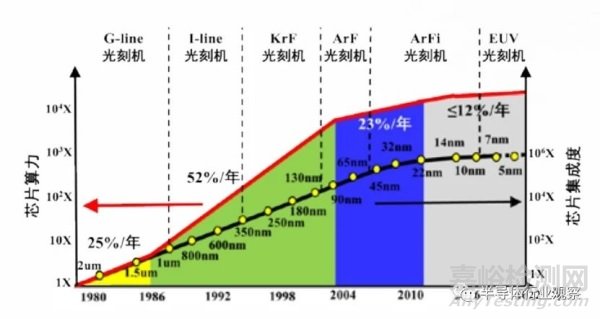
第一條路徑是通過(guò)將晶體管的尺寸不斷微縮實(shí)現(xiàn)集成密度和性能的指數(shù)式提升,也被稱為遵循“摩爾定律”的發(fā)展路徑�。1965 年戈登·摩爾指出,集成電路的晶體管數(shù)目大約每 18-24 個(gè)月增加一倍���。摩爾定律�、登納德縮放定律�、以及同時(shí)期的體系架構(gòu)創(chuàng)新,包括指令級(jí)并行�����、多核架構(gòu)等�,共同推動(dòng)了芯片性能隨工藝尺寸微縮的指數(shù)式提升�。
圖 2.3 提升芯片性能的第一條路徑 : 摩爾定律
隨著集成電路工藝進(jìn)入 5nm 以下,尺寸微縮接近物理極限�����,單純依靠縮小晶體管尺寸提高芯片性能的空間變小���,同時(shí)帶來(lái)了成本與復(fù)雜度的快速提高���。芯片散熱能力�����、傳輸帶寬�、制造良率等多種因素共同影響�����,形成了芯片功耗墻���、存儲(chǔ)墻�����、面積墻等瓶頸���,限制了單顆芯片的性能提升?����?梢哉f(shuō),摩爾定律的放緩已成為國(guó)際和我國(guó)集成電路發(fā)展的重大挑戰(zhàn)�。
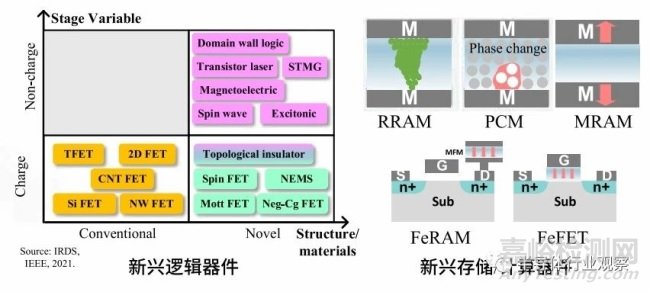
第二條路徑是通過(guò)發(fā)展新原理器件,研發(fā)新材料�,實(shí)現(xiàn)單個(gè)晶體管器件的性能提升。隨著鐵電存儲(chǔ)器 FeRAM�、阻變存儲(chǔ)器 RRAM、磁存儲(chǔ)器 MRAM���、相變存儲(chǔ)器 PCM���、鐵電晶體管 FeFET 等多種新原理器件的發(fā)展,結(jié)合寬禁帶半導(dǎo)體�、二維材料、碳納米管等新材料的研究�����,探索超越傳統(tǒng)CMOS 器件性能 / 能效的新型器件和突破馮諾依曼架構(gòu)的新型計(jì)算范式成為一個(gè)重要的研究領(lǐng)域�。然而,新原理器件是面向未來(lái)的芯片性能提升發(fā)展路徑,從科學(xué)研究到實(shí)際應(yīng)用的周期通常較長(zhǎng)�,難以在短時(shí)間內(nèi)解決當(dāng)前高性能集成電路芯片受限的挑戰(zhàn)。
圖 2.4 提升芯片性能的第二條路徑 : 新原理器件
隨著技術(shù)體系和產(chǎn)業(yè)生態(tài)逐漸構(gòu)建���,集成芯片將發(fā)展為芯片性能提升的第三條主路徑。芯片的性能主要取決于芯片集成的晶體管規(guī)模,而晶體管規(guī)模又取決于芯片制造面積�。集成芯片路徑能夠有效突破芯片制造的面積墻瓶頸。芯片的“面積墻”�����,是指單顆芯片的制造面積受限于光刻機(jī)可處理的極限尺寸和良率�����。一方面�����,最先進(jìn)的高性能芯片(如 NVIDIA H100 GPU 等)面積正在接近光刻面積極限�。同時(shí),單芯片良率隨面積增長(zhǎng)快速下降�����,在高成本的先進(jìn)工藝下�����,該問(wèn)題更加具有挑戰(zhàn)性�����。集成芯片能夠通過(guò)多顆芯粒與基板的 2.5D/3D 集成,突破單芯片光刻面積的限制和成品率隨面積下降的問(wèn)題���,成為進(jìn)一步提升芯片性能的可行路徑���。另外一方面,集成芯片技術(shù)是一條不單純依賴尺寸微縮路線提升芯片性能的重要途徑�,在短期內(nèi)難以突破自主 EUV 光刻機(jī)和先進(jìn)節(jié)點(diǎn)制造工藝的情況下,可以提供一條利用自主低世代集成電路工藝實(shí)現(xiàn)跨越 1-2 個(gè)工藝節(jié)點(diǎn)的高端芯片性能的技術(shù)路線���。
集成芯片這一第三條路徑與尺寸微縮�、新原理器件的前兩條路徑并不互斥�。三條路徑分別從不同的維度提升芯片性能,并能夠相輔相成�����。集成芯片能夠根據(jù)應(yīng)用的性能���、功耗、成本等需求進(jìn)行合理的功能劃分�����,最優(yōu)化各個(gè)芯粒的工藝節(jié)點(diǎn)。尺寸微縮路徑為集成芯片中單個(gè)芯粒的性能提升和芯粒間互連帶寬的提升提供了一個(gè)重要的設(shè)計(jì)維度�����;在制造工藝較為成熟之后�����,基于新原理器件的特定功能芯粒也可以引入到集成芯片中�����,為進(jìn)一步的性能和功能提升提供發(fā)展驅(qū)動(dòng)力���。
2.3 集成芯片將引導(dǎo)集成電路設(shè)計(jì)的新范式
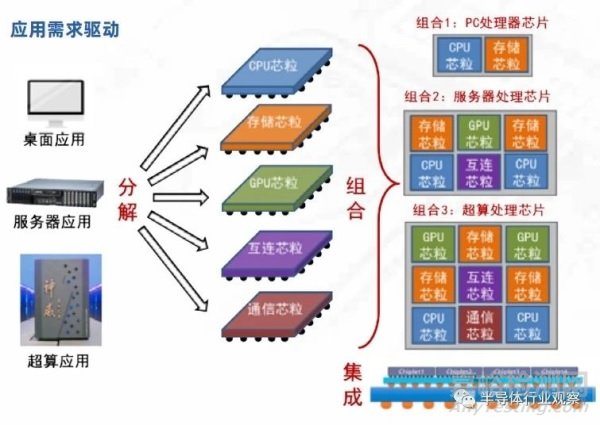
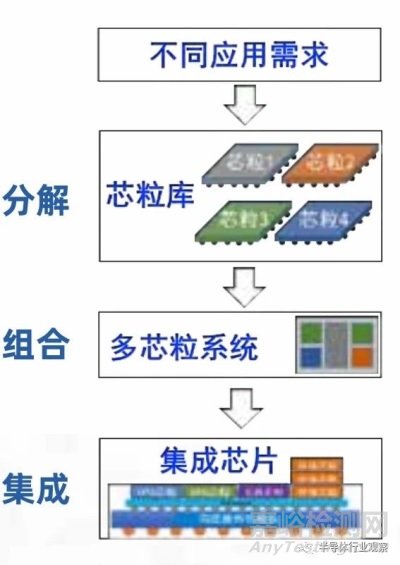
系統(tǒng)工程學(xué)中�����,即使元器件性能相對(duì)落后���,通過(guò)復(fù)雜系統(tǒng)跨學(xué)科優(yōu)化,也可以實(shí)現(xiàn)高性能系統(tǒng)���,或者反過(guò)來(lái)“如果一個(gè)一個(gè)局部構(gòu)件彼此不協(xié)調(diào)���,那么���,即使這些構(gòu)件的設(shè)計(jì)和制造從局部看是很先進(jìn)的,但這部機(jī)器的總體性能還是不合格的”���。集成芯片采用系統(tǒng)工程學(xué)的原理,發(fā)展自上而下構(gòu)造法的集成電路設(shè)計(jì)新范式�。自上而下意味著芯片結(jié)構(gòu)適配應(yīng)用特征�����,自上而下采用“分解 - 組合 - 集成”的方法���。根據(jù)應(yīng)用特征,抽象分解成若干標(biāo)準(zhǔn)的芯粒預(yù)制件�����,將眾多芯粒預(yù)制件�����,按照結(jié)構(gòu)組合成不同應(yīng)用領(lǐng)域的芯片�,將芯片制造分解為芯粒預(yù)制件的制造和多芯粒集成�����。下例展示了處理器芯片采用集成芯片范式后的新流程:
圖 2.5 自上而下的“分解 - 組合 - 集成”設(shè)計(jì)范式在處理器芯片上的示例
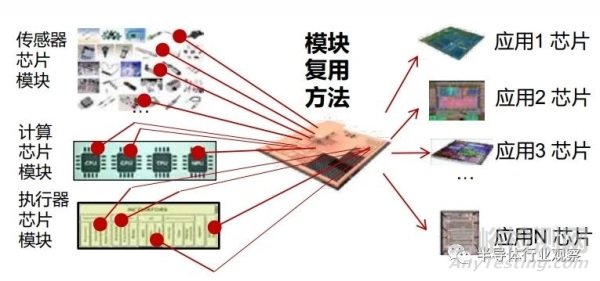
集成芯片將帶來(lái)基于芯粒復(fù)用的芯片敏捷設(shè)計(jì)方法���。未來(lái)�����,芯片的發(fā)展需要應(yīng)對(duì)物端計(jì)算系統(tǒng)碎片化�,多樣性的挑戰(zhàn) [11]�;同時(shí)�,每個(gè)芯片對(duì)應(yīng)的市場(chǎng)都較小,難以實(shí)現(xiàn)如 PC、手機(jī)芯片大的出貨量,這個(gè)矛盾現(xiàn)象也被稱為“昆蟲(chóng)綱悖論”——系統(tǒng)個(gè)性化和通用性的矛盾 [12]�。隨著芯片制程的不斷微縮�����,基于越先進(jìn)的工藝制程來(lái)設(shè)計(jì)物端芯片面臨的復(fù)雜度和設(shè)計(jì)成本將進(jìn)一步加劇上述問(wèn)題。現(xiàn)有的物端芯片的設(shè)計(jì)方法�,是將大量第三方 IP 與專有 IP 整合形成 SoC�,并在采用同一個(gè)制程工藝進(jìn)行制造。典型的 IP 包括 CPU�����、模擬傳感器�、存儲(chǔ)器���、加速器、接口驅(qū)動(dòng)等。上述在一個(gè)單芯片上集成的方案在設(shè)計(jì)復(fù)雜度和商業(yè)成本上難以解決昆蟲(chóng)綱悖論�����。
集成芯片技術(shù)為解決昆蟲(chóng)綱悖論提供了一條新思路。除了具有核心優(yōu)勢(shì)的專用“芯粒”外�,集成芯片設(shè)計(jì)廠商可以選擇第三方的“芯粒” 預(yù)制件形式提供的 IP���,通過(guò)半導(dǎo)體集成工藝將芯粒在一個(gè)封裝體內(nèi)相連接�����。上述方案能夠降低芯片設(shè)計(jì)難度�����,提升靈活性和效率�����,適應(yīng)各種碎片化應(yīng)用場(chǎng)景。商業(yè)上�����,上述方案僅對(duì)芯粒預(yù)制件的出貨量提出需求�,如 CPU�,藍(lán)牙 /Wifi 模組等核心模塊�����,可以大大降低商業(yè)成本,并規(guī)避單一芯片廠商可能造成的壟斷風(fēng)險(xiǎn)�����。集成芯片為碎片化的萬(wàn)物智能�、萬(wàn)物互連的人機(jī)物三元融合時(shí)代提供一種新的設(shè)計(jì)范式�。
圖 2.6 集成芯片設(shè)計(jì)新范式
2.4 集成芯片的現(xiàn)狀和趨勢(shì)
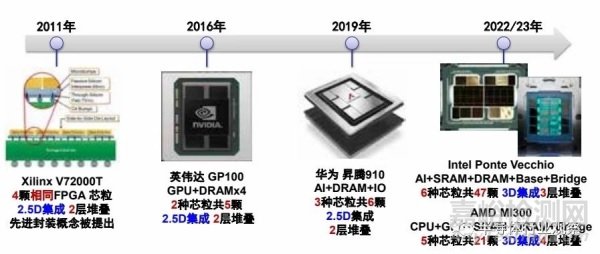
最早的集成芯片原型是由臺(tái)積電與美國(guó)賽靈思(Xilinx)公司共同完成的一款大容量 FPGA 芯片V7200T�,它將四個(gè)大規(guī)模的 FPGA 芯粒在一塊硅基板(Interposer)上連接在一起,形成一個(gè)超過(guò)2000 個(gè)可編程邏輯門的系統(tǒng)�����。借助這一芯片的開(kāi)發(fā)�����,臺(tái)積電也完成了基于半導(dǎo)體工藝的芯片互連封裝技術(shù)���,稱為 Chip-on-Wafer-on-Substrate(CoWoS)。目前這一技術(shù)作為 2.5D 集成芯片的代表性工藝,廣泛的應(yīng)用于高性能處理器芯片產(chǎn)品中�����。第一個(gè)采用 CoWoS 技術(shù)的處理器集成芯片是英偉達(dá)公司的 GP100 GPU 芯片�,它的結(jié)構(gòu)是通過(guò) CoWoS 工藝將 GPU 芯粒和多個(gè) HBM 芯粒在一個(gè)封裝體內(nèi)集成�,最大化處理器與存儲(chǔ)之間的通信帶寬�,硅基板尺寸超過(guò) 1 個(gè)光罩(858mm²)�。我國(guó)華為海思公司設(shè)計(jì)的昇騰 910 芯片 [3]�����,也是基于這一技術(shù)將 3 種、6 個(gè)芯粒的集成�,實(shí)現(xiàn)了高算力的人工智能處理器�。
圖 2.7 集成芯片朝向更多數(shù)量和種類的大規(guī)模方向
近年來(lái)���,隨著 TSV�����、銅 - 銅混合鍵合等工藝的成熟���,3D 集成芯片成為了高性能處理器領(lǐng)域新的發(fā)展趨勢(shì)�����。美國(guó) AMD 和 Intel 公司均基于 3D 集成芯片技術(shù),設(shè)計(jì)了面向超算的高性能超算處理器芯片���。上述產(chǎn)品將將 6-8 種���,超過(guò) 20 個(gè)芯粒的芯粒集成在一個(gè)系統(tǒng)中,最終實(shí)現(xiàn)了更大規(guī)模(千億以上規(guī)模數(shù)量級(jí)晶體管)、更復(fù)雜的集成。在 2.5D 集成上���,基于重分布層(Re-Distribution Layer)的扇出工藝(FanOut)可以實(shí)現(xiàn)更大規(guī)模的芯粒集成�,美國(guó) Tesla 公司基于 FanOut 工藝開(kāi)發(fā)面向人工智能的訓(xùn)練處理器集成芯片 DOJO�,RDL 基板的總面積達(dá)到 20000mm²�,包含 25 個(gè) D1 多核處理器芯粒和光電融合的通信芯粒�。
我國(guó)研發(fā)機(jī)構(gòu)在高集成度上取得了進(jìn)展�。比較有代表性的包含,2022 年中科院計(jì)算所智能計(jì)算機(jī)中心和之江實(shí)驗(yàn)室聯(lián)合開(kāi)發(fā)了“之江大芯片一號(hào)”�����,該芯片成果集成了 16 個(gè)芯粒,每個(gè)芯粒含 16個(gè) CPU 核�,無(wú)論是集成的芯粒數(shù)和體系結(jié)構(gòu)上的計(jì)算核心數(shù)���,都實(shí)現(xiàn)了突破,從體系架構(gòu)和設(shè)計(jì)方法學(xué)上�,驗(yàn)證了利用集成芯片突破單處理器芯片的算力極限技術(shù)途徑。目前�,正在開(kāi)展“之江大芯片二號(hào)”的工作,集成度和性能將進(jìn)一步提升�。2022 年,復(fù)旦大學(xué)集成芯片與系統(tǒng)全國(guó)重點(diǎn)實(shí)驗(yàn)室基于集成扇出封裝工藝實(shí)現(xiàn)了存算一體 2.5D 芯片�����,采用片間按層流水的可擴(kuò)展架構(gòu)實(shí)現(xiàn)了系統(tǒng)算力與存儲(chǔ)規(guī)模的按芯粒比例的線性增長(zhǎng),避免了“一系統(tǒng)一設(shè)計(jì)”的高復(fù)雜度問(wèn)題�。此外,阿里達(dá)摩院聯(lián)合紫光國(guó)芯研發(fā)基于 3D 混合鍵合工藝的智能加速器 -DRAM 堆疊集成芯片���,豪威科技的采用三層堆疊工藝將圖像傳感器芯粒�、模擬讀出電路芯粒�、圖像信號(hào)處理與 AI 芯粒集成為一個(gè)組件,面向像素的不斷提升���,最小化芯粒間的通信開(kāi)銷。
圖 2.8 (a) 之江大芯片 1 號(hào)�����;(2)存算一體 2.5D 芯片
集成芯片中���,由于每個(gè)芯粒由不同的單位設(shè)計(jì)�����,因此接口的標(biāo)準(zhǔn)化是系統(tǒng)能夠高效率組合的關(guān)鍵因素�。在 Intel 的主導(dǎo)下�,2022 年 3 月�����,通用高速接口聯(lián)盟(Universal Chiplet Interconnect Express�����,UCIe)正式成立�,旨在構(gòu)建芯粒技術(shù)在芯片上的互聯(lián)標(biāo)準(zhǔn)�。在我國(guó),中國(guó)計(jì)算機(jī)互連技術(shù)聯(lián)盟的《小芯片接口總線技術(shù)要求》和中關(guān)村高性能芯片互聯(lián)技術(shù)聯(lián)盟的《芯?����;ヂ?lián)接口規(guī)范》等接口規(guī)范也已公布���。
3�����、集成芯片的架構(gòu)與電路設(shè)計(jì)
3.1 從集成芯片到芯粒:分解與組合的難題
集成芯片采用了“分解 - 組合 - 集成”的新設(shè)計(jì)范式���。“分解”是指根據(jù)不同應(yīng)用的特征,抽象出若干標(biāo)準(zhǔn)的芯粒預(yù)制件���;“組合”指將眾多的芯粒預(yù)制構(gòu)件按照某種結(jié)構(gòu)組合設(shè)計(jì)成不同應(yīng)用領(lǐng)域所需要的專用芯片和系統(tǒng)���。根據(jù)目標(biāo)應(yīng)用�����,構(gòu)建最優(yōu)的芯粒分解 - 組合設(shè)計(jì)方法是重要的技術(shù)難題���。
( 一 ) 芯粒分解研究
出于成本、安全性�、系統(tǒng)性能等多重因素的考量,學(xué)術(shù)界和工業(yè)界持續(xù)關(guān)注芯粒分解技術(shù)�。
成本因素�����。摩爾定律的放緩與日益增長(zhǎng)的性能需求導(dǎo)致芯片面積日益增長(zhǎng)���。這不僅引發(fā)了芯片良率的下降���,還降低了晶圓的利用率,拉高了芯片的制造成本���。學(xué)術(shù)界對(duì)芯粒系統(tǒng)的成本進(jìn)行了分析建模���,它由 RE 成本(Recurring Engineering Cost)與 NRE 成本(Non-Recurring Engineering Cost)構(gòu)成�。RE 成本是每片芯片制造都要支付的成本���,包括晶圓���、封裝、測(cè)試的成本等���。NRE 成本指研發(fā)�、制造芯片產(chǎn)品時(shí)所支付的一次性費(fèi)用�,包括人力成本、IP 授權(quán)費(fèi)用�、光罩成本等。UCSB 提出的模型表明 RE 成本受到芯粒工藝�����、系統(tǒng)規(guī)模�����、封裝良率等多重因素的影響 [18]。清華大學(xué)的模型 [19] 將 NRE 成本表示為系統(tǒng)總體���、各個(gè)芯粒�、芯粒中包含模塊的 NRE 成本之和�。
圖3.1 芯粒的分解與組合
安全性因素。Fabless 的模式帶來(lái)了諸如版圖泄露�����、硬件木馬植入等安全風(fēng)險(xiǎn)�。分離制造 [15] 通過(guò)將芯片分為多個(gè)部件分別交于不同的晶圓廠,使晶圓廠無(wú)法獲得芯片的全部信息���,來(lái)保護(hù)信息不被泄露���。而基于分解的芯粒技術(shù)天然地具有分離制造的特性�����,并且相較于傳統(tǒng)的基于金屬層過(guò)孔的分離制造方法�,芯粒使用標(biāo)準(zhǔn)的片間通信接口,在工藝上降低了封裝的難度。
此外���,芯粒分解需要從系統(tǒng)角度綜合考慮�。芯粒分解雖然能夠降低成本�����、提高芯片良率和安全性�,但是會(huì)引入芯粒間通信的功耗、性能開(kāi)銷以及額外面積開(kāi)銷�����。因此�����,芯粒分解不能僅關(guān)注單個(gè)芯粒構(gòu)件的設(shè)計(jì)�,需要對(duì)整條產(chǎn)品線進(jìn)行分析,以發(fā)掘芯粒在多個(gè)產(chǎn)品中的復(fù)用機(jī)會(huì)�。工業(yè)界目前已經(jīng)出現(xiàn)多個(gè)將復(fù)雜功能芯片分解為多個(gè)芯粒構(gòu)件的工作:AMD 在第二代 EPYC 架構(gòu)中將計(jì)算與 IO 部分拆分為不同的芯粒 [7];海思基于 LEGO 理念�����,將 SoC 分解為 CPU 計(jì)算、計(jì)算 I/O���、AI 計(jì)算等少量的芯粒���,并利用它們組合出多種產(chǎn)品 [8];Intel 也將芯粒技術(shù)應(yīng)用到了 FPGA�、CPU、GPU 等產(chǎn)品上���,其中 Ponte Vecchio GPU 被分解為計(jì)算���、存儲(chǔ)、通信等芯粒�����,數(shù)量高達(dá) 47 塊 [9]�。
現(xiàn)有的芯粒分解方案往往依賴于設(shè)計(jì)人員的經(jīng)驗(yàn),這種手工的分解方式難以窮盡所有的設(shè)計(jì)空間�,產(chǎn)生的效益、開(kāi)銷也往往不是最優(yōu)的 [20]�����。因此���,當(dāng)前亟需自動(dòng)化芯粒分解技術(shù)�。目前已有一些簡(jiǎn)單的劃分策略�,如將設(shè)計(jì)拆分為多個(gè)相同芯粒的均勻劃分方式 [18],與基于最小割算法的均衡劃分方式[21]�����。這些技術(shù)缺乏對(duì)成本���、性能�、功耗的綜合優(yōu)化���,也沒(méi)有在多個(gè)硬件設(shè)計(jì)中尋找可重用芯粒的能力���。
( 二 ) 芯粒組合研究
芯粒組合過(guò)程中,設(shè)計(jì)人員根據(jù)用戶輸入的應(yīng)用與優(yōu)化目標(biāo)�����,從芯粒庫(kù)中選出最優(yōu)芯粒并組合�����。工業(yè)界和學(xué)術(shù)界對(duì)這一問(wèn)題也開(kāi)展了探索:zGlue[22] 提供了包含 MCU、傳感器等芯粒的庫(kù)�����,用戶可以根據(jù)自己的需求手動(dòng)地選擇集成的芯粒�����;海思利用 CPU 芯粒 +I/O 芯粒組合出服務(wù)器所需的芯片���,利用 AI 計(jì)算芯粒 + 計(jì)算 /IO 芯粒組合出針對(duì) AI 訓(xùn)練的芯片 [8]���;通過(guò)使用不同數(shù)量的 CPU 計(jì)算芯粒,AMD 組合出了包含不同核數(shù)的服務(wù)器芯片 [7]�����。由于缺乏統(tǒng)一的接口標(biāo)準(zhǔn)���,目前工業(yè)界的實(shí)踐主要為in-house 芯粒的組合�����。
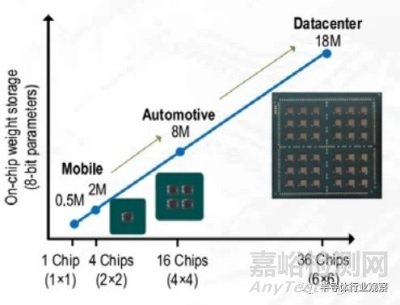
現(xiàn)有的芯粒組合方案 [8][9] 往往是手動(dòng)設(shè)計(jì)的���,集成效率低且缺乏深層優(yōu)化,這也催生了自動(dòng)化芯粒組合的研究���。UCLA 提出了面向處理器的芯粒組合框架 [23]�,用以尋找針對(duì)多個(gè)應(yīng)用負(fù)載的最優(yōu)芯粒系統(tǒng)集合�����,其優(yōu)化目標(biāo)為系統(tǒng)功耗�����、性能�����、成本等���。計(jì)算所提出了一套敏捷芯粒集成框架 [24]�����,可以自動(dòng)根據(jù)用戶輸入的應(yīng)用描述�����,從芯粒庫(kù)中選擇出性能���、面積�、成本等指標(biāo)最優(yōu)的芯粒組合�,并且完成應(yīng)用任務(wù)在芯粒上的映射。無(wú)論是面向通用應(yīng)用的多 CPU 芯粒 [7] 與多 GPU 芯粒 [25] 的組合�����,還是面向?qū)S妙I(lǐng)域的芯粒組合�,均可以通過(guò)集成不同數(shù)量的芯粒來(lái)獲得不同性能的系統(tǒng)。如圖 3.2 所示�,面向 AI 領(lǐng)域的 Simba[27] 系統(tǒng)以被靈活拓展,形成適用于各個(gè)場(chǎng)景的產(chǎn)品�����,也有學(xué)者提出了能搜索針對(duì)單個(gè)應(yīng)用和多個(gè)特定應(yīng)用的芯粒組合框架 [23][24]�。
圖 3.2 AI 系統(tǒng)性能與芯粒數(shù)量組合的關(guān)系 [27]
無(wú)論是芯粒分解還是芯粒組合,都是復(fù)雜的優(yōu)化問(wèn)題,依靠人力難以應(yīng)對(duì)龐大的搜索空間�����,這也給予了設(shè)計(jì)自動(dòng)化工具和大規(guī)模集成芯片仿真器新的機(jī)遇�。在芯粒時(shí)代,我們需要更高效的 EDA 工具來(lái)更進(jìn)一步地優(yōu)化系統(tǒng)成本�,降低集成開(kāi)銷�����,促進(jìn)芯粒生態(tài)繁榮�����。
3.2 芯粒間互連網(wǎng)絡(luò)
與片上網(wǎng)絡(luò)(Network-on-Chihp)相對(duì)應(yīng)�,基板上網(wǎng)絡(luò)(Network-on-Interposer)實(shí)現(xiàn)芯粒間互連互通,作為各處理單元間的數(shù)據(jù)傳輸基礎(chǔ)設(shè)施�,是影響數(shù)據(jù)通信性能和功耗的關(guān)鍵,包含互連拓?fù)?、路由和容錯(cuò)機(jī)制三個(gè)關(guān)鍵技術(shù)。
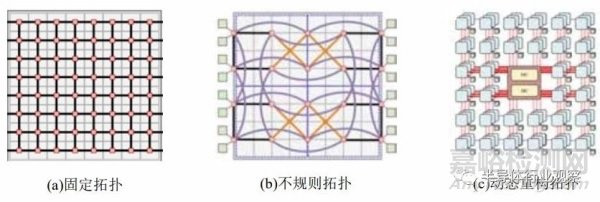
(一) 互連拓?fù)?/span>
從互連網(wǎng)絡(luò)的通信效率進(jìn)行考慮���,網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)從固定���、簡(jiǎn)單的通用拓?fù)浣Y(jié)構(gòu)演進(jìn)到不規(guī)則和可重構(gòu)拓?fù)浣Y(jié)構(gòu)�����,以適配不同的應(yīng)用數(shù)據(jù)傳輸需求�。通用互連網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)設(shè)計(jì)簡(jiǎn)便�����,適用于多種數(shù)據(jù)通信場(chǎng)景�����。但是通用性和性能互為制約���,通用拓?fù)浣Y(jié)構(gòu)設(shè)計(jì)并不能提供最高的通信效率���。因此,不規(guī)則和可重構(gòu)的互連拓?fù)浣Y(jié)構(gòu)以降低通用性為代價(jià)���,提供了更高性能的互連解決方案�����。
網(wǎng)格(Mesh)以及環(huán)形曲面(Torus)等基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu)�����,由于其結(jié)構(gòu)簡(jiǎn)單規(guī)則�����,是芯粒間網(wǎng)絡(luò)中最為廣泛使用的通用拓?fù)?,典型拓?fù)渚W(wǎng)格結(jié)構(gòu)如圖 3.3 所示。采用通用拓?fù)錁?gòu)成互連網(wǎng)絡(luò)的有NVIDIA 的 Simba[27] �����,其芯粒內(nèi)與芯粒間均采用了網(wǎng)格型拓?fù)?����,Conical-Fishbone 時(shí)鐘域網(wǎng)絡(luò)中使用的無(wú)緩沖網(wǎng)格拓?fù)?����。MCM-3D-NoC[29] 架構(gòu)基于有源基板�,芯粒間采用芯粒堆疊互連的三維(3D)堆疊拓?fù)浣Y(jié)構(gòu)���。此外�����,POPSTAR[30][31] 基于光電連接的芯粒間環(huán)形(Ring)結(jié)構(gòu)�,以及無(wú)緩沖多環(huán)(Multi-Ring)結(jié)構(gòu) [32] 屬于通用拓?fù)洹?/span>
圖 3.3 典型的拓?fù)渚W(wǎng)絡(luò) [35][43]
當(dāng)網(wǎng)絡(luò)流量不均衡或動(dòng)態(tài)變化,通用���、規(guī)則的拓?fù)浣Y(jié)構(gòu)無(wú)法適配當(dāng)前流量需求將導(dǎo)致?lián)砣?��,而不?guī)則拓?fù)浣Y(jié)構(gòu)則可以根據(jù)相應(yīng)流量特征優(yōu)化網(wǎng)絡(luò)鏈路或結(jié)構(gòu),以獲得更高性能�。Kite 拓?fù)湎盗?[35]基于基板上網(wǎng)絡(luò)(Network-on-Interposer)和片上網(wǎng)絡(luò)(NoC)的頻率異質(zhì)性,在頻率限制下最大化有效鏈長(zhǎng)���,減少跳數(shù)降低延遲�,提高網(wǎng)絡(luò)吞吐量�。與常見(jiàn)通用拓?fù)浣Y(jié)構(gòu)相比,Kite 拓?fù)浣Y(jié)構(gòu)中使用了更多不同長(zhǎng)度和不同方向的鏈路�,提高通信效率。此外�����,除有線鏈路的不規(guī)則設(shè)計(jì)外,也有一些設(shè)計(jì)方案基于多芯粒無(wú)線接口互連技術(shù) [36][37][38]���,支持芯粒間多方式互連�,可實(shí)現(xiàn)多種不規(guī)則網(wǎng)絡(luò)拓?fù)洹?/span>
不規(guī)則拓?fù)浣Y(jié)構(gòu)針對(duì)應(yīng)用的通信流量需求進(jìn)行了優(yōu)化�����,然而不同應(yīng)用的流量特征差異極大且存在動(dòng)態(tài)時(shí)變特征�,因此出現(xiàn)了能夠根據(jù)應(yīng)用流量動(dòng)態(tài)變化的可重構(gòu)拓?fù)浣Y(jié)構(gòu),動(dòng)態(tài)地根據(jù)應(yīng)用需求進(jìn)行重配置�。Adapt-NoC[39] 架構(gòu)采用 SMART[40] 構(gòu)建自適應(yīng)芯粒路由,可重構(gòu)鏈路設(shè)計(jì) [41] 在有源基板中連接子網(wǎng)絡(luò)���,并且動(dòng)態(tài)分配鏈路帶寬以提高網(wǎng)絡(luò)吞吐量�,采用 Panthre[42] 技術(shù)進(jìn)行網(wǎng)絡(luò)拓?fù)渲嘏渲?,將網(wǎng)絡(luò)劃分為多個(gè)子網(wǎng)絡(luò)���,使每個(gè)子網(wǎng)絡(luò)可以根據(jù)通信需求提供不同的網(wǎng)絡(luò)拓?fù)?��。中科院?jì)算所提出了可重構(gòu)基板網(wǎng)絡(luò)(NoI)設(shè)計(jì)方法 [43] 基于胖樹(shù)生成適應(yīng)各種分布式訓(xùn)練模式的拓?fù)洌蛇m應(yīng)各種神經(jīng)網(wǎng)絡(luò)應(yīng)用�����,特別采用了環(huán)和樹(shù)結(jié)合的拓?fù)浣Y(jié)構(gòu)適用于數(shù)據(jù)并行中的數(shù)據(jù)交換。
可重構(gòu)拓?fù)湓试S根據(jù)應(yīng)用數(shù)據(jù)傳輸需求進(jìn)行動(dòng)態(tài)配置和調(diào)整�,提供了高靈活性、高適應(yīng)性�����、高性能的解決方案�����。然而�,如何實(shí)現(xiàn)更大規(guī)模的動(dòng)態(tài)可重構(gòu)互連拓?fù)浣Y(jié)構(gòu)設(shè)計(jì)和容錯(cuò)機(jī)制,并實(shí)現(xiàn)互連架構(gòu)的準(zhǔn)確性能評(píng)估�,仍是芯粒間互連網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)設(shè)計(jì)的重要挑戰(zhàn)。
(二) 路由
路由算法是影響集成系統(tǒng)通信開(kāi)銷的另一重要因素���,其決定了數(shù)據(jù)傳輸?shù)穆窂介L(zhǎng)度和可靠性���。為了能夠適配多種復(fù)雜的互連網(wǎng)絡(luò)方案,同時(shí)考慮芯?��;ミB集成設(shè)計(jì)方案的立體化趨勢(shì)���,需要面向芯粒集成的系統(tǒng)特性進(jìn)行路由算法設(shè)計(jì)���。
芯粒集成系統(tǒng)的路由算法需要滿足以下特性:1)拓?fù)錈o(wú)關(guān)性,路由算法應(yīng)該能夠適用于通用和不規(guī)則的拓?fù)浣Y(jié)構(gòu)�����,而不僅限于特定的拓?fù)?。這樣可以適應(yīng)不同芯粒集成方案中可能存在的多樣化互連網(wǎng)絡(luò)拓?fù)洹?)完全可達(dá)性,若源和目的地之間存在路徑���,路由算法應(yīng)該始終能夠找到該條可行的路徑�。即使是復(fù)雜的垂直堆疊和基板互連結(jié)構(gòu)�����,路由算法也應(yīng)確保算法能夠指出能夠從源芯粒傳輸?shù)侥康男玖5目尚新窂健?)故障獨(dú)立性���,路由算法需要具備對(duì)節(jié)點(diǎn)或鏈路故障的容錯(cuò)能力。當(dāng)發(fā)生故障時(shí)�����,路由算法應(yīng)該能夠重新計(jì)算路徑,繞過(guò)故障節(jié)點(diǎn)或鏈路�,保證數(shù)據(jù)傳輸?shù)目煽啃院瓦B通性。4)可擴(kuò)展性�,路由算法引入的開(kāi)銷應(yīng)是獨(dú)立的,或者僅隨著網(wǎng)絡(luò)規(guī)模的變化而變化�。無(wú)論系統(tǒng)中有多少個(gè)芯粒或多復(fù)雜的堆疊結(jié)構(gòu)���,路由算法都應(yīng)該能夠高效地處理通信需求�,而不會(huì)導(dǎo)致性能下降或通信開(kāi)銷過(guò)大�����。
在設(shè)計(jì)面向芯粒集成的系統(tǒng)的路由算法時(shí)�,需要根據(jù)具體的集成方案和系統(tǒng)需求進(jìn)行算法的優(yōu)化和定制,這樣可以實(shí)現(xiàn)高效可靠的數(shù)據(jù)傳輸���,適應(yīng)復(fù)雜的互連網(wǎng)絡(luò)結(jié)構(gòu)�����,并充分發(fā)揮芯粒集成技術(shù)的優(yōu)勢(shì)���。
(三) 容錯(cuò)機(jī)制
在面向芯粒集成的互連網(wǎng)絡(luò)設(shè)計(jì)中���,考慮到單個(gè)芯粒內(nèi)集成了更高數(shù)量級(jí)的晶體管和先進(jìn)制程的不完善,因此故障率相對(duì)較高���。為了應(yīng)對(duì)永久性故障帶來(lái)的系統(tǒng)性能損失�����,可以采取以下優(yōu)化措施提升系統(tǒng)的容錯(cuò)性能:容錯(cuò)拓?fù)湓O(shè)計(jì)和容錯(cuò)路由�����。
容錯(cuò)拓?fù)涫侵冈谛玖ig的互連設(shè)計(jì)中�,通過(guò)采用能夠容忍故障和提供冗余路徑的結(jié)構(gòu)布局方式�,提升系統(tǒng)的容錯(cuò)性能。容錯(cuò)拓?fù)淇梢圆扇∫韵虏呗裕海?)冗余網(wǎng)絡(luò)�。使用多條路徑建立芯粒之間的通信連接,如果某條路徑發(fā)生故障���,可以通過(guò)其他路徑進(jìn)行通信�����,保證數(shù)據(jù)傳輸?shù)目煽啃院瓦B通性���。(2)高連接性網(wǎng)絡(luò)。高連接性網(wǎng)絡(luò)的目標(biāo)是確保大多數(shù)節(jié)點(diǎn)具有較高的節(jié)點(diǎn)基數(shù)�,從而為網(wǎng)絡(luò)提供路徑多樣性,并以此增強(qiáng)系統(tǒng)的容錯(cuò)能力���,對(duì)于次要節(jié)點(diǎn)���,可以適當(dāng)?shù)慕档凸?jié)點(diǎn)基數(shù)以減小硬件開(kāi)銷。
容錯(cuò)路由是指在芯粒間的互連設(shè)計(jì)中�����,通過(guò)設(shè)計(jì)能夠應(yīng)對(duì)永久性故障導(dǎo)致的網(wǎng)絡(luò)變化的路由算法���,提升系統(tǒng)的容錯(cuò)性能�。當(dāng)網(wǎng)絡(luò)中出現(xiàn)錯(cuò)誤時(shí)�����,路由算法需要具備適應(yīng)網(wǎng)絡(luò)變化的能力�,并自適應(yīng)的執(zhí)行不同的路由策略以繞過(guò)或避免故障區(qū)域的通信,這也是容錯(cuò)路由的重要研究方向。為了提升錯(cuò)誤處理能力�����,容錯(cuò)路由算法可以采取以下策略:(1)動(dòng)態(tài)路徑選擇���。路由算法可以根據(jù)實(shí)時(shí)的網(wǎng)絡(luò)狀態(tài)和錯(cuò)誤信息�����,動(dòng)態(tài)選擇最佳路徑來(lái)繞過(guò)故障區(qū)域�����。這可以通過(guò)監(jiān)測(cè)鏈路狀態(tài)�����、節(jié)點(diǎn)負(fù)載�����、延遲等指標(biāo)來(lái)實(shí)現(xiàn)�����。路由算法可以基于這些信息做出即時(shí)的路由決策�,將數(shù)據(jù)流量導(dǎo)向可用的路徑。(2)基于負(fù)載均衡的路由���。當(dāng)網(wǎng)絡(luò)中出現(xiàn)故障時(shí),路由算法可以考慮負(fù)載均衡策略來(lái)選擇路徑�����。它可以根據(jù)節(jié)點(diǎn)的負(fù)載狀況�,選擇相對(duì)較空閑的路徑進(jìn)行通信,以避免將更多的流量導(dǎo)向已經(jīng)過(guò)載或故障的區(qū)域���。國(guó)內(nèi)中科院計(jì)算所早期在研究 3D TSV 設(shè)計(jì)時(shí)���,針對(duì) TSV 提出了復(fù)用容錯(cuò)的技術(shù)思路 [44]和容錯(cuò) NOC 設(shè)計(jì) [50],清華大學(xué)���、合肥工業(yè)大學(xué)等也有相關(guān)研究 [51][52]�。
3.3 芯?;ミB的接口協(xié)議
現(xiàn)有面向芯粒的接口協(xié)議主要分為兩類:物理層接口協(xié)議和完整的協(xié)議棧。大多數(shù)物理層接口協(xié)議或標(biāo)準(zhǔn)主要關(guān)注引腳定義���、電氣特性�����、bump map 等基礎(chǔ)特性�����,可以保證數(shù)據(jù)比特流的點(diǎn)對(duì)點(diǎn)傳輸�����。在此基礎(chǔ)上�,協(xié)議棧對(duì)路由方式、數(shù)據(jù)結(jié)構(gòu)�、可靠傳輸機(jī)制、一致性���、流量控制等做了更詳細(xì)的規(guī)定�����,一般可以建立端到端的可靠數(shù)據(jù)傳輸�。
(一) 物理層
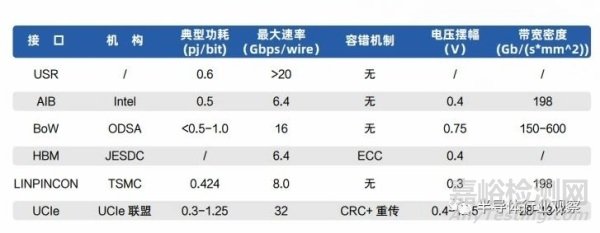
美國(guó)英特爾公司率先提出了 AIB (Advanced Interface Bus)�,用于規(guī)范芯粒間互連的物理層協(xié)議���,可適應(yīng)不同制造和封裝工藝 [45]。一個(gè) AIB 接口由一個(gè)或多個(gè) AIB 通道組成���,每個(gè)通道包含 20-640根數(shù)據(jù)線���,兩對(duì)差分時(shí)鐘以及用于初始化的邊帶信號(hào)。AIB 在單線極大的數(shù)據(jù)速率下�����,以擴(kuò)展位寬的方式獲得高帶寬���。此外,AIB 可以通過(guò)啟用冗余的 bump 來(lái)規(guī)避封裝缺陷�,以此來(lái)實(shí)現(xiàn)一定程度的容錯(cuò)功能。
由 Facebook�、AMD 等企業(yè)共同發(fā)起的 ODSA(Open Domain-Specific Architecture)聯(lián)盟提出了 BoW(Bunch of Wires)并行接口協(xié)議,BoW 的模塊化的接口可對(duì)應(yīng)標(biāo)準(zhǔn)封裝和先進(jìn)封裝工藝 [46]�����。每個(gè) BoW 模塊包括 16 根數(shù)據(jù)線和一對(duì)差分時(shí)鐘�����,BoW 復(fù)用主數(shù)據(jù)通路進(jìn)行參數(shù)協(xié)商和初始化,無(wú)專用的邊帶信號(hào)���。在 14nm 工藝下���,Bow 以 16Gbps/wire 的傳輸速率以及 50mm 線長(zhǎng),可達(dá)到 0.7pj/bit 的較低功耗���,誤碼率為 1E-15�����。
與上述面向通用數(shù)據(jù)連接的接口不同�,HBM(High Bandwidth Memory) 接口是 JEDEC(Joint Electron Device Engineering Council) 定義���,專門用于連接 HBM 內(nèi)存的并行總線接口 [47]�。最新的HBM3 最多支持 16 個(gè)獨(dú)立通道���,每個(gè)通道的數(shù)據(jù)位寬為 64�,包含 10 位行地址線和 8 位列地址線���,最高數(shù)據(jù)速率為 6.4Gbps�。此外,HBM 支持通過(guò) 4 位 ECC 進(jìn)行糾錯(cuò)�。
此外,盡管 Chiplet 物理接口大多走的是并行化方向���,但追求高速率的 Serdes 接口依靠著更高的帶寬密度受到關(guān)注�����。USR(Ultra-Short-Reach)是一種主要面向chiplet片間互聯(lián)的Serdes接口[48]�,可以使用單端信號(hào)或差分信號(hào)進(jìn)行數(shù)據(jù)傳輸�����,在 20Gb/s 的傳輸速率下能夠達(dá)到 0.6pj/bit 的功耗�����,相比于普通的 Serdes 接口有著很大優(yōu)勢(shì)���。然而,相比于寬度更大的并行接口���,USR 在帶寬上存在劣勢(shì)�。
隨著 3D 封裝的進(jìn)展,單獨(dú)支持 2.5D 的互連已經(jīng)無(wú)法滿足需求�。因此,臺(tái)積電提出了兼容 2.5D和 3D 的高能效 LIPINCON (Low-voltage-in-package-inter- connect) 互連接口協(xié)議 [49]���。其可在0.8V 的電壓和 0.3V 的電壓擺幅下實(shí)現(xiàn) 0.84UI 的眼寬和 75% 擺幅的眼高�,而其 256 的數(shù)據(jù)位寬和8Gbps/wire 的數(shù)據(jù)速率有待提升�����。
(二) 協(xié)議棧
芯粒間的數(shù)據(jù)傳輸有許多重要的功能需求�,如對(duì)核間數(shù)據(jù)通信業(yè)務(wù)邏輯的詳細(xì)規(guī)定、數(shù)據(jù)傳輸可靠性�����、緩存一致性���、路由策略等�。而物理層協(xié)議僅能保證通信雙方物理電氣特性上的互聯(lián)互通�����,因此,構(gòu)建完整的上層協(xié)議對(duì)芯粒接口至關(guān)重要�。
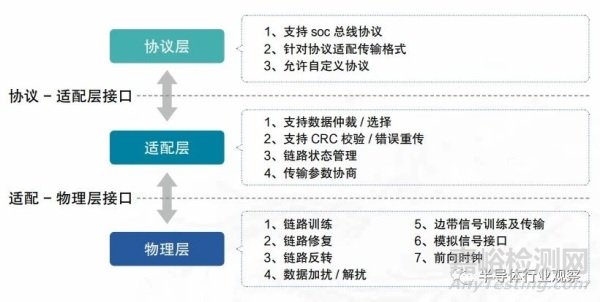
ODSA 首先注意到了完整協(xié)議棧的重要性,并于 2021 年提出了一種面向芯?;ミB的協(xié)議架構(gòu),該架構(gòu)由協(xié)議層�����、鏈路層和物理層構(gòu)成�。其中,物理層方案為 BoW 接口�����,建議在協(xié)議層復(fù)用現(xiàn)有協(xié)議�,鏈路層通過(guò) CRC 校驗(yàn)和重傳機(jī)制實(shí)現(xiàn)可靠傳輸?shù)幕舅悸贰?/span>
圖 3.11 UCIe 層級(jí)與功能
2022 年,UCIe(Universal Chiplet Interconnect Express)聯(lián)盟公布了 UCIe 協(xié)議���。與 ODSA 的架構(gòu)類似,UCIe 由協(xié)議層�����、片間適配層和物理層構(gòu)成�。UCIe 協(xié)議層沿用成熟的 PCIe 和 CXL 協(xié)議以實(shí)現(xiàn)對(duì)現(xiàn)有生態(tài)的最大兼容�����,片間適配層則利用 CRC 校驗(yàn)以及重傳機(jī)制保證數(shù)據(jù)傳輸?shù)目煽啃?����。UCIe 在物理層采用 AIB 接口�����,在電氣特性上具有廣泛兼容性的同時(shí)���,可實(shí)現(xiàn)物理通道損壞的自動(dòng)檢測(cè)和通道重映射等功能。UCIe 是 chiplet 完整協(xié)議棧的典型代表�,其物理層的模塊化設(shè)計(jì)、容錯(cuò)功能�����、以及鏈路層的校驗(yàn)重傳機(jī)制契合 chiplet 應(yīng)用場(chǎng)景�。因此,設(shè)計(jì)全新的上層協(xié)議——既定義面向chiplet 間數(shù)據(jù)傳輸?shù)臉I(yè)務(wù)邏輯或許是以后 chiplet 接口協(xié)議發(fā)展的重點(diǎn)�����。
在國(guó)內(nèi),由中科院計(jì)算所牽頭的團(tuán)標(biāo) T/CESA 1248—2023 是中國(guó)電子工業(yè)標(biāo)準(zhǔn)化技術(shù)協(xié)會(huì)于2023 年發(fā)布的面向 chiplet 的接口協(xié)議棧�,由協(xié)議層、鏈路層和物理層組成���。T/CESA 1248 的層次結(jié)構(gòu)和功能劃分與 UCIe 類似���,既協(xié)議層使用 PCIe 和 CXL 實(shí)現(xiàn)業(yè)務(wù)邏輯,鏈路層實(shí)現(xiàn)可靠傳輸�����,物理層規(guī)定物理電氣特性等�。T/CESA 1248 是國(guó)內(nèi)最早的面向芯粒接口的互聯(lián)標(biāo)準(zhǔn)。
當(dāng)前面向芯粒的接口標(biāo)準(zhǔn)以并行接口為主���,且強(qiáng)調(diào)物理接口的模塊化�����,可以充分利用先進(jìn)封裝的高互連密度特性并最大化接口帶寬。此外 AIB�����、BOW、HBM�����、UCIe 等主要接口協(xié)議均采用大寬度單端數(shù)據(jù) + 隨路時(shí)鐘的方案�����,僅 USR 等少部分協(xié)議采用高速串行數(shù)據(jù) + 時(shí)鐘恢復(fù)方案�。在芯粒技術(shù)帶來(lái)的芯片設(shè)計(jì)積木化、敏捷化與定制化的場(chǎng)景下���,芯?;ヂ?lián)協(xié)議需與廠商�����、架構(gòu)�、制造工藝解耦,擁有廣泛的兼容性與開(kāi)放性�,才能適應(yīng)芯粒異構(gòu)互聯(lián)、跨廠商互聯(lián)的實(shí)際需求���。
3.4 芯粒間的高速接口電路
芯粒間通信是基于高速接口電路完成的 , 它和傳統(tǒng)的 PCB 級(jí)高速鏈路之間有一些相似之處�����,但也存在著關(guān)鍵的區(qū)別:1)超短距離:在一個(gè)封裝體內(nèi)���,芯粒間互連距離通常小于 1 厘米���,甚至可以小于 1 毫米,信道的損耗迅速降低���,更利于高帶寬設(shè)計(jì)�����;2)高密度:采用半導(dǎo)體制造工藝(光刻���、蝕刻),芯粒間互連線間距可以在微米級(jí)�����,在單位面積下可以更高并行度���;3)低功耗與低延遲:芯片粒間互連重點(diǎn)關(guān)注功耗效率�、延遲和性能優(yōu)化進(jìn)行。
芯粒間的高速接口電路包括以下幾類:1)面向 2.5D/3D 集成工藝的有線(Wireline)并行通信接口�;2)基于電感耦合的無(wú)線互連通信接口;3)高帶寬光電互連接口�����。
并行互連接口技術(shù)通過(guò)大量信道同時(shí)進(jìn)行并行傳輸���,以達(dá)到 Tbps 級(jí)別的傳輸帶寬。因此���,它不追求單線絕對(duì)速率與帶寬�����,在 UCIe/AIB 等協(xié)議中,每根線的傳輸速率也僅為 32Gbps。實(shí)際設(shè)計(jì)中,芯片設(shè)計(jì)企業(yè)可以根據(jù)系統(tǒng)要求設(shè)計(jì)信道并行數(shù)量和單線速率�。因此可以在不使用連續(xù)時(shí)間線性均衡器(CTLE)�����、時(shí)鐘數(shù)據(jù)恢復(fù)電路(CDR)等大功耗模擬電路模塊的情況下實(shí)現(xiàn)信號(hào)的傳輸。并行電路的時(shí)鐘信號(hào)可以通過(guò)獨(dú)立的信道進(jìn)行傳輸,同時(shí)利用數(shù)控延時(shí)單元(DCDL)�、相位插值器(PI)和占空比調(diào)節(jié)器(DCC)來(lái)實(shí)現(xiàn)數(shù)據(jù)和時(shí)鐘信號(hào)的校準(zhǔn)���,這些電路的結(jié)構(gòu)相對(duì)簡(jiǎn)單���,由于多個(gè)數(shù)據(jù)信道可以共用一組時(shí)鐘線,因此對(duì)整個(gè)收發(fā)電路的面積影響也較小���。相較于傳統(tǒng)串行接口,并行互聯(lián)具有能效高(<1 pJ/bit)���、延遲低�、設(shè)計(jì)簡(jiǎn)單的優(yōu)點(diǎn)���,能夠?qū)崿F(xiàn)更高的集成芯片互聯(lián)密度和更高效的芯粒間互聯(lián)�����。
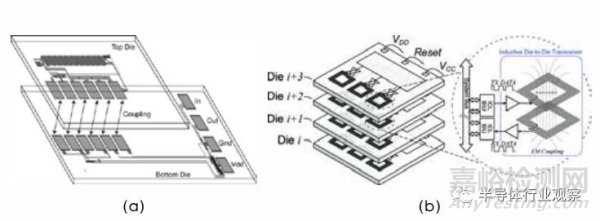
無(wú)線互連接口也是芯粒間互聯(lián)的一種解決方案�����。它的優(yōu)勢(shì)是不依賴先進(jìn)封裝工藝特別是 TSV�����,可以完全兼容現(xiàn)有的 CMOS 工藝���。其互連是通過(guò)芯粒間電感耦合實(shí)現(xiàn)的�?����;陔姼械幕ミB接口在兩個(gè)芯粒上各放置一個(gè)線圈���,通過(guò)線圈間的電磁耦合傳遞無(wú)線信號(hào)�,如圖 3.12 所示�。但是考慮到在電感的面積,無(wú)線互連的能效和速率方面相對(duì)于有線互連方案并無(wú)優(yōu)勢(shì)�����。此外���,無(wú)線互連只適用于 3D的封裝堆疊方式�,不適用于 2.5D 等其它形式的集成芯片。
光互連接口是更前瞻的芯粒間的接口方案�����,它通過(guò)集成在硅晶圓上的八波長(zhǎng)分布式反饋(DFB)激光器陣列和光波導(dǎo)�����,可以實(shí)現(xiàn)單線低功耗�����、高性能�、太比特每秒(TBps)的互連速率,較電互連高出一個(gè)數(shù)量級(jí)���。但是在芯粒種實(shí)現(xiàn)光互連還需解決很多問(wèn)題,比如集成激光器陣列如何縮小體積�����、降低成本���、如何兼容現(xiàn)有 CMOS 工藝�,完成異質(zhì)封裝。
圖 3.12 基于 (a) 電容耦合 (b) 電感耦合的芯粒間無(wú)線互聯(lián)方式
在芯?��;ミB的高速接口上���,仍然存在這多個(gè)科學(xué)問(wèn)題,如突破功耗瓶頸的新電路�����,兼容不同信道的可重構(gòu)收發(fā)機(jī)���,自適應(yīng)檢測(cè)與校正機(jī)制�、接口電路的跨工藝自動(dòng)化遷移等���。應(yīng)對(duì)這些挑戰(zhàn)需要多學(xué)科交叉研究�,涉及電路設(shè)計(jì)���、電磁場(chǎng)信號(hào)完整性分析���、熱管理、制造工藝等領(lǐng)域的專業(yè)知識(shí)���。
3.5 多芯粒系統(tǒng)的存儲(chǔ)架構(gòu)
系集成芯片中�,多芯粒的存儲(chǔ)結(jié)構(gòu)是影響集成芯片的訪存性能和功耗的重要因素。集成芯片的存儲(chǔ)結(jié)構(gòu)與傳統(tǒng)的眾核或服務(wù)器芯片存儲(chǔ)結(jié)構(gòu)有較多相似性�����,主要的優(yōu)化目標(biāo)為提高訪存性能�、降低目錄等開(kāi)銷。因此�,多芯粒系統(tǒng)的存儲(chǔ)架構(gòu)主要從多級(jí)存儲(chǔ)結(jié)構(gòu)的組織方式和存儲(chǔ)管理兩方面進(jìn)行優(yōu)化。
多芯粒系統(tǒng)的訪存性能受限于物理結(jié)構(gòu)所提供的帶寬�����,隨著平面存儲(chǔ)結(jié)構(gòu)的帶寬和性能已接近極限�,多芯粒系統(tǒng)存儲(chǔ)結(jié)構(gòu)的組織方式也逐漸從平面存儲(chǔ)結(jié)構(gòu)向垂直存儲(chǔ)結(jié)構(gòu)發(fā)展。與傳統(tǒng)的水平存儲(chǔ)方式相比�����,它在垂直方向上堆疊存儲(chǔ)單元�,從而實(shí)現(xiàn)更高的存儲(chǔ)密度和容量�����。其核心思想是充分利用垂直方向的空間增加存儲(chǔ)單元的數(shù)量。
在垂直存儲(chǔ)中�����,存儲(chǔ)單元以垂直方向堆疊在一起���,形成多層結(jié)構(gòu)�。每一層都包含多個(gè)存儲(chǔ)單元�����,通過(guò)垂直連接結(jié)構(gòu)進(jìn)行數(shù)據(jù)傳輸和訪問(wèn)�。這種垂直堆疊的方式大大減小了存儲(chǔ)器的占地面積,使得在相同的面積下�����,相比于水平排布的存儲(chǔ)形式���,可以容納更多的存儲(chǔ)單元�,從而提供更大的存儲(chǔ)容量�����。由于存儲(chǔ)單元之間更近的距離,數(shù)據(jù)的傳輸路徑更短�����,因此可以實(shí)現(xiàn)更快的數(shù)據(jù)訪問(wèn)速度和更低的訪問(wèn)延遲���。此外�����,垂直存儲(chǔ)結(jié)構(gòu)還可以提供更高的數(shù)據(jù)帶寬�����,允許同時(shí)訪問(wèn)多個(gè)存儲(chǔ)層�����,從而進(jìn)一步提升數(shù)據(jù)訪問(wèn)性能�。
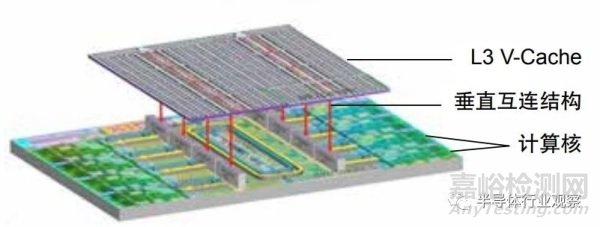
垂直存儲(chǔ)技術(shù)已經(jīng)在各種領(lǐng)域得到應(yīng)用���,例如�,在 3D NAND 中�,多層存儲(chǔ)單元沿各層之間的互連以垂直的形式進(jìn)行疊加。在實(shí)現(xiàn)更短的整體連接的同時(shí)�,提高了存儲(chǔ)的容量,并減小了存儲(chǔ)硬件占用的空間相較于傳統(tǒng)的 2D NAND�����,每字節(jié)的存儲(chǔ)成本也更低�����。Zen3[64] 在垂直方向上引入高速緩存3D V-Cache�,額外的緩存層可以提供更高的緩存容量與更低的延遲,從而提升訪存性能�。處理器內(nèi)的核心可以更頻繁地訪問(wèn)高速緩存中的數(shù)據(jù),從而減少對(duì)主內(nèi)存的訪問(wèn)�,提高數(shù)據(jù)訪問(wèn)速度。這些方案利用垂直存儲(chǔ)的優(yōu)勢(shì)���,實(shí)現(xiàn)了更高的存儲(chǔ)容量�����、更快的數(shù)據(jù)訪問(wèn)速度和更可靠的數(shù)據(jù)存儲(chǔ)���。
圖 3.4 Zen3 處理器垂直方向緩存示意圖 [64]
多芯粒系統(tǒng)的存儲(chǔ)通常采用非一致內(nèi)存訪問(wèn)結(jié)構(gòu)(Non-Uniform Memory Access�����,NUMA)�,NUMA 結(jié)構(gòu)提供了高效的共享數(shù)據(jù)方式和靈活的資源分配方案���,但相應(yīng)地需要解決如何加速跨核心的數(shù)據(jù)訪問(wèn)�����、提升維持?jǐn)?shù)據(jù)一致性的通信速度�。層次化緩存一致性協(xié)議和目錄已被廣泛研究用于芯片多處理器 [53][54] 和多芯粒服務(wù)器 (multi-socket) 系統(tǒng) [55]�����。在全局?jǐn)?shù)據(jù)訪問(wèn)中�����,芯粒間緩存一致性管理訪存開(kāi)銷較大�����。因此,降低緩存一致性開(kāi)銷的方法可以分為減少維護(hù)一致性的數(shù)據(jù)流量和針對(duì)互連結(jié)構(gòu)優(yōu)化一致性協(xié)議兩類�。減少一致性流量的根本原理在于發(fā)掘和消除一致性流量中的冗余,當(dāng)連續(xù)寫(xiě)入的次數(shù)達(dá)到閾值時(shí)�,通過(guò)執(zhí)行一次寫(xiě)更新來(lái)優(yōu)化傳統(tǒng)的多次寫(xiě)入更新協(xié)議可減少寫(xiě)緩存的開(kāi)銷[57]���。另外���,由于不同存儲(chǔ)層級(jí)的開(kāi)銷不同���,因此可將共享讀寫(xiě)緩存行移動(dòng)到更低級(jí)別的緩存以減少上級(jí)緩存的寫(xiě)無(wú)效流量 [56]。
針對(duì)互連結(jié)構(gòu)優(yōu)化一致性協(xié)議也是降低一致性開(kāi)銷的重要方法�����。考慮到多芯粒系統(tǒng)在芯粒間和芯粒內(nèi)具有不同的通信結(jié)構(gòu)和開(kāi)銷�����,使用 Snoop 與目錄式混合的緩存一致性協(xié)議 [58]���,通過(guò)全局協(xié)議和本地目錄協(xié)議分別實(shí)現(xiàn)芯粒間和芯粒內(nèi)的緩存一致性可以大幅降低一致性開(kāi)銷。新的互連方式也為一致性協(xié)議提供了新的優(yōu)化空間�����,WiDir[61] 結(jié)合片上無(wú)線網(wǎng)絡(luò)技術(shù)來(lái)增強(qiáng)傳統(tǒng)的基于無(wú)效目錄的緩存一致性協(xié)議�,以程序員透明的方式�,根據(jù)訪問(wèn)模式���,有線和無(wú)線一致性事務(wù)之間進(jìn)行無(wú)縫轉(zhuǎn)換���。相比于傳統(tǒng)的電網(wǎng)絡(luò)�,基于硅光子技術(shù)的互連網(wǎng)絡(luò)有望實(shí)現(xiàn)更高寬帶和更低延遲���。PCCN[59] 作為一種基于光子緩存一致性網(wǎng)絡(luò)的物理集中式邏輯分布式目錄協(xié)議,采用帶有競(jìng)爭(zhēng)的機(jī)制解決信道共享問(wèn)題�����,實(shí)現(xiàn)高效的長(zhǎng)距離一致性相關(guān)數(shù)據(jù)包的傳輸�。小型低成本硅光子 CAMON 芯粒 [60] 可以有效緩解多核處理器的通信瓶頸問(wèn)題���,提高數(shù)據(jù)移動(dòng)的能效���,在多芯粒系統(tǒng)尤其是大規(guī)模系統(tǒng)中發(fā)揮了重要作用。
3.6 集成芯片大功率供電電路
隨著芯粒集成規(guī)模的提升�����,集成芯片的供電系統(tǒng)面臨新的挑戰(zhàn)。目前單顆高性能芯片的功耗大約在百瓦量級(jí)�����,例如 Intel 13 代 CPU 的 PL2 TDP 為 219W,NVIDIA H100 GPU TDP 為 350W�����。面向未來(lái)百芯粒規(guī)模的集成芯片���,其供電需求將達(dá)到數(shù)千瓦甚至萬(wàn)瓦級(jí)。結(jié)合集成芯片的特點(diǎn)�,研發(fā)新型萬(wàn)瓦級(jí)供電電路���,是大規(guī)模芯粒集成必須解決的關(guān)鍵難題���。
集成芯片的供電系統(tǒng)面臨多方面的約束���。集成芯片對(duì)外的接口數(shù)量有限,部分芯粒完全集成在系統(tǒng)內(nèi)部���,沒(méi)有直接對(duì)外的接口,因此需要在集成芯片的內(nèi)部進(jìn)行整個(gè)系統(tǒng)的電源管理�����。大規(guī)模芯粒集成能夠采用 TSV 進(jìn)行芯粒間的供電傳輸�,但 TSV 的電流密度受限,萬(wàn)瓦級(jí)供電所需的 TSV 數(shù)量將嚴(yán)重影響整個(gè)集成芯片系統(tǒng)的面積�����。大量芯粒在不同的供電電壓和電流下同時(shí)工作���,需要設(shè)計(jì)高效的電源分配網(wǎng)絡(luò)�,解決芯粒間供電電流不均衡和動(dòng)態(tài)變化等問(wèn)題�,保障芯粒穩(wěn)定工作并提高能效比�����。同時(shí)�����,供電電路需要集成大面積的電容�、電感等無(wú)源器件保持供電穩(wěn)定,傳統(tǒng)封裝可以在 PCB 板級(jí)集成這些無(wú)源器件���,而在高集成度的集成芯片系統(tǒng)中,如何在內(nèi)部集成這些無(wú)源器件是一個(gè)新的挑戰(zhàn)���。
為實(shí)現(xiàn)集成芯片萬(wàn)瓦級(jí)供電的技術(shù)路線,需要研究包括多級(jí)供電架構(gòu)���、電源分配網(wǎng)絡(luò)和無(wú)源器件集成等多種技術(shù)�����。多級(jí)供電電路在第一級(jí)采用較高的供電電壓(如 12V)���,在相同供電功率下通過(guò)提高電壓解決 TSV 電流密度受限的問(wèn)題。在后級(jí)供電電路采用高效率的 DC-DC 電路�,將高供電電壓轉(zhuǎn)換為芯粒內(nèi)部所需的較低工作電壓(如 1V)。多級(jí)供電電路的一個(gè)重要挑戰(zhàn)是如何在較先進(jìn)工藝節(jié)點(diǎn)實(shí)現(xiàn)高電壓的供電電路�����,并針對(duì)負(fù)載功率大幅跳變的情況實(shí)現(xiàn)快速響應(yīng)���。為實(shí)現(xiàn)高效的電源分配網(wǎng)絡(luò),需要研究電源網(wǎng)絡(luò)受到供電電壓�、傳輸路徑長(zhǎng)度、寄生效應(yīng)等的影響關(guān)系�,探索三維垂直供電架構(gòu)和動(dòng)態(tài)電源分配技術(shù)等���。同時(shí),針對(duì)供電電路中大面積無(wú)源器件在集成芯片內(nèi)部的集成�,一種技術(shù)方案是利用 TSV 的電感特性�,并在大面積基板上實(shí)現(xiàn)電容���、電感等無(wú)源器件�����,實(shí)現(xiàn)內(nèi)部集成。
集成芯片的萬(wàn)瓦級(jí)供電是大規(guī)模芯粒集成必須解決的關(guān)鍵技術(shù)�����。需要從多級(jí)供電架構(gòu)�、電源分配網(wǎng)絡(luò)和無(wú)源器件集成等多個(gè)方面開(kāi)展研究���,保障集成芯片的供電穩(wěn)定性�����,提升供電效率�����,并縮減供電系統(tǒng)的體積���。萬(wàn)瓦級(jí)供電需要與集成芯片的散熱技術(shù)進(jìn)行聯(lián)合設(shè)計(jì)優(yōu)化�����。同時(shí),可以結(jié)合單芯粒的背面供電(如 Intel PowerVia)等技術(shù)實(shí)現(xiàn)更高的供電效率�。
4�����、集成芯片EDA和多物理場(chǎng)仿真
4.1 集成芯片對(duì)自動(dòng)化設(shè)計(jì)方法與EDA工具的新需求
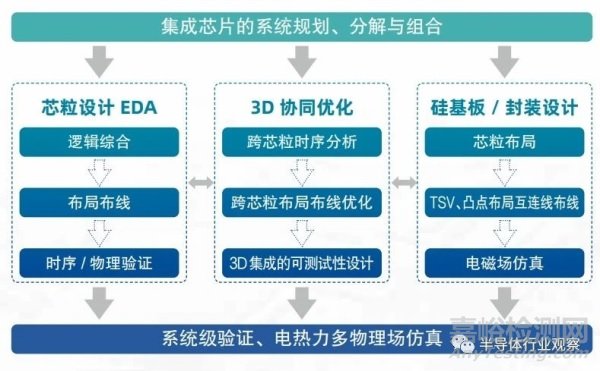
集成芯片的規(guī)模遠(yuǎn)遠(yuǎn)大于普通的單芯片規(guī)模�,若芯片設(shè)計(jì)的復(fù)雜度與晶體管數(shù)量成比例關(guān)系�����,那么集成芯片的設(shè)計(jì)面臨復(fù)雜度指數(shù)級(jí)發(fā)展的困境。因此�,面向集成芯片設(shè)計(jì)���,需要更多的自動(dòng)化設(shè)計(jì)EDA 工具�����。
圖 4.1 集成芯片的自動(dòng)化設(shè)計(jì)方法與 EDA 工具
圖 4.1 歸納了集成芯片對(duì)自動(dòng)化設(shè)計(jì)方法的 EDA 工具的新需求�����,具體包括:
(一)集成芯片的系統(tǒng)規(guī)劃與分解組合:用于在具體設(shè)計(jì)之前的集成芯片的系統(tǒng)設(shè)計(jì)規(guī)劃���,完成各個(gè)功能的功能與性能的初步設(shè)計(jì)空間探索;
(二)芯粒設(shè)計(jì):與典型的 VLSI 設(shè)計(jì)方法和 EDA 類似���,包含邏輯綜合���、布局布線與時(shí)序 / 物理設(shè)計(jì)的驗(yàn)證等部分;
(三)硅基板(Interposer)和封裝設(shè)計(jì):用于實(shí)現(xiàn)芯粒間互連���,需要解決芯粒的布局優(yōu)化�����,芯粒間互連線布線���、TSV/ 微凸點(diǎn) / 植球的布局等物理設(shè)計(jì)���,對(duì)于有源硅基板還要覆蓋芯粒的 EDA 設(shè)計(jì)工具完成其電路部分的設(shè)計(jì);
(四)3D 協(xié)同優(yōu)化設(shè)計(jì):用于在芯粒和基板封裝設(shè)計(jì)后的協(xié)同優(yōu)化與驗(yàn)證���,如芯粒 - 基板互連后的跨芯粒時(shí)序分析�����、布局布線優(yōu)化�,同時(shí)還需要考慮 3D 集成的可測(cè)性設(shè)計(jì)�����,因?yàn)樵?3D 集成后部分芯粒已無(wú)對(duì)外直接可測(cè)的引腳�����,需專用方案;
(五)系統(tǒng)級(jí)驗(yàn)證與多物理場(chǎng)仿真:用于準(zhǔn)確捕獲和分析系統(tǒng)內(nèi)電—熱—力發(fā)生的復(fù)雜交互和現(xiàn)象,需要將多個(gè)物理場(chǎng)集成到一個(gè)統(tǒng)一的仿真框架中,上述物理量的交互作用包括由于封裝材料的熱膨脹系數(shù)的差異和結(jié)構(gòu)不匹配���,在不同的工作負(fù)載下產(chǎn)生不同的熱分布�,并導(dǎo)致硅片的翹曲���、封裝裂紋和分層。
其中�����,互連線的電磁場(chǎng)仿真和自動(dòng)化布線�、電 - 熱 - 力多物理場(chǎng)仿真和 3D 集成芯片的可測(cè)性設(shè)計(jì)是集成芯片設(shè)計(jì)的全新 EDA 問(wèn)題�。
4.2 芯粒間互連線的電磁場(chǎng)仿真與版圖自動(dòng)化
伴隨著芯粒數(shù)量和種類的增加�,芯粒間互連線數(shù)也急劇增加�����??梢灶A(yù)計(jì)���,未來(lái)的芯粒間互連線數(shù)量將達(dá)到十萬(wàn)甚至百萬(wàn)量級(jí)規(guī)模�����,靠手工布線的可行性低。片上布線與芯粒間布線的基礎(chǔ)電學(xué)約束上存在差異,導(dǎo)致已有的片上布線的 EDA 工具難以應(yīng)用到集成芯片的片間。在單個(gè)芯片內(nèi)���,金屬布線通常涉及更高密度的互連和更復(fù)雜的布線架構(gòu)���,一般在網(wǎng)格上根據(jù)延遲的約束條件實(shí)現(xiàn)自動(dòng)化布線,還可以通過(guò)內(nèi)插緩沖電路來(lái)避免過(guò)長(zhǎng)(100 微米以上)的互連線�����。在芯粒間,互連線尺寸一般在微米級(jí)�,并且無(wú)法內(nèi)插緩沖器,因此需要將高速通信的信號(hào)完整性作為主要約束條件���。
精確且快速的電磁場(chǎng)仿真對(duì)于滿足集成芯片的信號(hào)完整性約束起到重要支撐作用。2.5D/3D 集成工藝引入的微凸點(diǎn)�����、TSV 結(jié)構(gòu)具有復(fù)雜的寄生效應(yīng)���,對(duì)信號(hào)的影響難以用 RLC 集總電路模型準(zhǔn)確評(píng)估。因此需要使用電磁場(chǎng)計(jì)算方法得到 S 參數(shù)模型�。增強(qiáng)電場(chǎng)積分方程方法(Enhanced Electric Field Integral Equation�,EFIE)是一種針對(duì)分層互連線結(jié)構(gòu)進(jìn)行電磁仿真的有效方法�。根據(jù)互連線的幾何模型�����,將互連線離散化為有限個(gè)小單元�����。通過(guò)對(duì)離散化的小單元應(yīng)用增強(qiáng)電場(chǎng)積分方程,可以建立一個(gè)線性方程組描述電磁場(chǎng)和電流的關(guān)系,該方法可以通過(guò)數(shù)值或者解析的方法求解�。求解得到電流分布后,再將電流分布與增強(qiáng)電場(chǎng)積分方程中的格林函數(shù)相乘,可以計(jì)算互連線上的電場(chǎng)分布。EFIE 方程可通過(guò)矩量法 (Method of Method���,MoM) 和有限元法(Finite Element Method���,F(xiàn)EM)求解。矩量法是基于積分形式麥克斯韋方程的頻域求解方法,它主要求解金屬表面的電流分布�,然后根據(jù)格林函數(shù)計(jì)算空間中任意點(diǎn)的電磁場(chǎng)。矩量法的優(yōu)點(diǎn)是計(jì)算速度快�����,消耗資源少,適合求解三維層狀結(jié)構(gòu)�。矩量法的缺點(diǎn)是對(duì)非均勻介質(zhì)和任意形狀的結(jié)構(gòu)求解效率低,精度受限于網(wǎng)格劃分和格林函數(shù)選擇�,不適合求解大信號(hào)和非線性問(wèn)題。
相比之下���,有限元等其基于微分形式麥克斯韋方程的頻域求解方法�����,雖然可求解任意形狀和材料的結(jié)構(gòu)�,精度高�,但是計(jì)算速度慢�����,消耗資源多�����,需要對(duì)整個(gè)空間進(jìn)行網(wǎng)格劃分,不適合求解開(kāi)放空間和時(shí)變問(wèn)題�。伴隨集成芯片芯粒數(shù)和互連線數(shù)規(guī)模急劇增長(zhǎng),現(xiàn)有的電磁場(chǎng) S 參數(shù)模型的提取效率低���,嚴(yán)重拖慢了仿真速度�����,影響集成芯片的設(shè)計(jì)和迭代過(guò)程�。同時(shí)���,由于芯粒間互連線的約束條件為電磁場(chǎng)�����,因此由電磁場(chǎng)驅(qū)動(dòng)的芯粒間互連線的版圖自動(dòng)化算法與 EDA 工具成為了集成芯片領(lǐng)域新的科學(xué)問(wèn)題�����。在考慮仿真精度的前提下�,縮短信號(hào)完整分析仿真時(shí)間的新算法是可以攻克上述問(wèn)題的重要方向�。
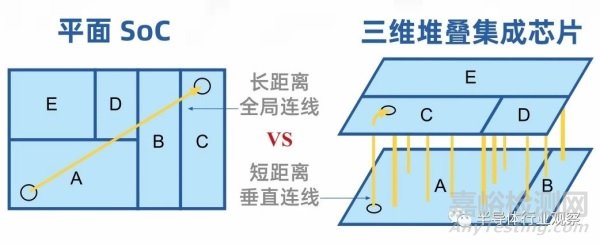
除了互連線的自動(dòng)化物理設(shè)計(jì)外���, 3D 集成芯片的布局布線也迎來(lái)了新的機(jī)遇和挑戰(zhàn)。在下圖所示的平面芯片三維堆疊集成芯片的比較中�����,我們可以看到���,在單芯片內(nèi)長(zhǎng)距離的全局連線可以被堆疊后的短距離的垂直線所替代�。因此�����,堆疊后的短距離線較長(zhǎng)距離線有望從毫米級(jí)縮小到百微米量級(jí)���,顯著提升互連線的負(fù)責(zé)和驅(qū)動(dòng)功耗�����。然而���,上述性能的提升是建立在高維度布局布線優(yōu)化算法的基礎(chǔ)上的�����。傳統(tǒng)的布局布線優(yōu)化方法,如模擬退火(Simulated Annealing)�����,迷宮路由(Maze Routing)���、遺傳算法等還未從理論個(gè)上突破平面維度的限制���。目前,三維堆疊芯片的布局布線 EDA工具僅支持粗粒度優(yōu)化——將存儲(chǔ)宏單元和邏輯宏單元分布在不同的芯粒上���,根據(jù)最小化距離優(yōu)化宏單元的布局布線�。更細(xì)粒度的三維布局布線方法需要新更進(jìn)一步的探索���。
圖 4.2 平面芯片與三維堆疊集成芯片的對(duì)比
4.3 芯粒尺度的電—熱—力多場(chǎng)耦合仿真
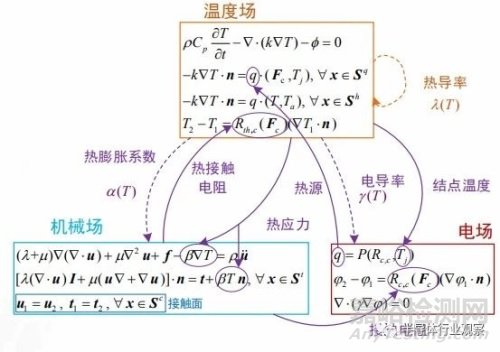
隨著集成電路的發(fā)展�,芯片與系統(tǒng)越來(lái)越小型化�、緊湊化,系統(tǒng)集成度也越來(lái)越高���。面向未來(lái)集成芯片中大規(guī)模芯粒集成的需求���,芯粒尺度的電 - 熱 - 力多場(chǎng)耦合仿真也愈發(fā)重要���。集成芯片集成非常復(fù)雜,需要協(xié)同考慮電磁場(chǎng)�、熱管理和機(jī)械應(yīng)力耦合作用,并進(jìn)行綜合優(yōu)化���。芯粒尺度的多物理場(chǎng)仿真是揭示芯粒和集成芯片在多物理場(chǎng)(例如電磁���、熱、力場(chǎng))同時(shí)耦合作用下�,提高性能的有效手段。為了實(shí)現(xiàn)對(duì)芯粒尺度集成的高保真模擬���,必須同時(shí)考慮具有多尺度���、非線性場(chǎng)相關(guān)材料的特性和非線性界面條件的精細(xì) 3D 幾何形狀。如何構(gòu)建芯粒尺度多物理場(chǎng)的基礎(chǔ)理論及其準(zhǔn)確仿真工具是集成芯片可制造性的重要挑戰(zhàn)���。
圖 4.3 集成芯粒中的電 - 熱 - 力耦合示意圖
封裝技術(shù)的發(fā)展推動(dòng)著芯片系統(tǒng)向更高頻率和更高功率發(fā)展���。電路特征尺寸的不斷減小和封裝系統(tǒng)復(fù)雜性的增加(例如集成芯片技術(shù))�����,對(duì)封裝設(shè)計(jì)提出了新的挑戰(zhàn),必須解決高頻�、高功率、應(yīng)力變化條件下的電磁分布效應(yīng)�����、熱效應(yīng)和力學(xué)效應(yīng)問(wèn)題���。隨著特征尺寸減小和功率增加���,溫度顯著升高,尤其是在熱點(diǎn)處�,會(huì)降低電子封裝的性能和使用壽命,并通過(guò)電遷移導(dǎo)致金屬化失效���。大的溫度梯度和不匹配的熱膨脹系數(shù)會(huì)產(chǎn)生誘導(dǎo)熱應(yīng)力���,可能導(dǎo)致芯粒的機(jī)械故障,例如分層和剝離等�。由于高溫引起的材料電磁特性的變化會(huì)導(dǎo)致信號(hào)完整性和電源完整性問(wèn)題���,例如時(shí)鐘偏移、意外壓降以及濾波器和諧振器的頻譜偏移�。因此,需要一種基于電 - 熱 - 力多物理場(chǎng)耦合的計(jì)算機(jī)輔助設(shè)計(jì)方法來(lái)同時(shí)解決電氣問(wèn)題和熱問(wèn)題�����。
圖 4.3 展示了用于分析集成芯片電 - 熱 - 力多物理場(chǎng)耦合關(guān)系的示意圖�����。建立足夠準(zhǔn)確和寬適用范圍的多物理場(chǎng)耦合模型進(jìn)行數(shù)值計(jì)算���,是在激勵(lì)或邊界條件等真實(shí)工況下模擬芯粒尺度先進(jìn)封裝的基礎(chǔ)���。多物理場(chǎng)仿真中的關(guān)鍵問(wèn)題包括由偏微分方程 (PDE) 或代數(shù)方程制定的多物理場(chǎng)耦合機(jī)制、考慮多個(gè)場(chǎng)強(qiáng)相互作用的材料本構(gòu)關(guān)系模型���、耦合 PDE 和傳遞機(jī)制的數(shù)值離散化以及有效求解復(fù)雜代數(shù)方程問(wèn)題等 [66][67]���。電 - 熱 - 力多場(chǎng)耦合仿真技術(shù)的復(fù)雜性呈指數(shù)增長(zhǎng),對(duì)先進(jìn)封裝技術(shù) [65]和相關(guān)的設(shè)計(jì)技術(shù)(如數(shù)值模擬)提出了更高的要求。在封裝技術(shù)的設(shè)計(jì)過(guò)程中���,包括材料參數(shù)�、對(duì)象和布局尺寸的選擇�����,盡早采用數(shù)值模擬方法進(jìn)行探索和試錯(cuò)�,可以顯著降低試驗(yàn)成本�����。
綜上所述�,隨著集成電路技術(shù)的發(fā)展和芯片系統(tǒng)集成度的提升,面向集成芯片的可制造性需求���,芯粒尺度的電 - 熱 - 力多場(chǎng)耦合仿真技術(shù)愈發(fā)重要�。多物理場(chǎng)仿真可以幫助評(píng)估芯粒設(shè)計(jì)性能參數(shù)���、調(diào)查故障機(jī)制�、提高可靠性并改進(jìn)封裝方法�。多物理場(chǎng)耦合求解的主要問(wèn)題和最終目標(biāo)是實(shí)現(xiàn)穩(wěn)定、可靠���、快速和準(zhǔn)確的數(shù)值計(jì)算�。這種計(jì)算的前提是數(shù)學(xué)模型本身的清晰合理的發(fā)展,以及對(duì)物理過(guò)程基本原理的理解���。為了提高模擬結(jié)果的準(zhǔn)確性和可靠性���,未來(lái)的研究重點(diǎn)包括先進(jìn)的數(shù)值模擬優(yōu)化算法和加速求解方法,開(kāi)發(fā)更精確的材料模型�,結(jié)合更全面的環(huán)境條件,通過(guò)實(shí)驗(yàn)驗(yàn)證實(shí)現(xiàn)對(duì)多物理場(chǎng)耦合效應(yīng)的準(zhǔn)確模擬���。
4.4 集成芯片的可測(cè)性和測(cè)試
集成芯片的可測(cè)性和測(cè)試技術(shù)相比傳統(tǒng)芯片面臨許多新的挑戰(zhàn)�����。集成芯片的制造良率需要考慮兩部分:?jiǎn)晤w芯粒自身的良率和多芯粒封裝過(guò)程的良率�����。為保證集成芯片的良率�,需要對(duì)每一顆芯粒進(jìn)行缺陷測(cè)試�����,并對(duì)芯粒封裝過(guò)程進(jìn)行良率測(cè)試。如果存在缺陷的芯粒在基板上集成���,或者封裝過(guò)程中產(chǎn)生缺陷���,整個(gè)集成芯片將無(wú)法實(shí)現(xiàn)預(yù)期功能。
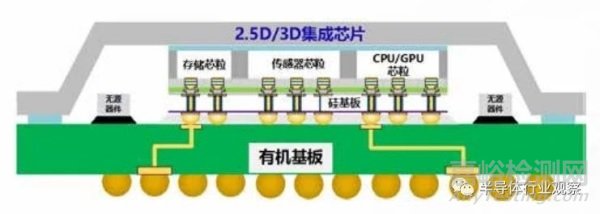
如圖 4.4 所示�����,針對(duì)集成芯片測(cè)試�,需要從單顆芯粒的測(cè)試技術(shù)和封裝互連的測(cè)試技術(shù)兩方面開(kāi)展新的探索�。針對(duì)單顆芯粒的測(cè)試技術(shù),通過(guò)使用探針臺(tái)結(jié)合單個(gè)芯粒的 DFT(Design for Testing)結(jié)構(gòu)進(jìn)行測(cè)試 [69]�����。為了提升集成芯片的良率�,還需要進(jìn)行 KGD(Known Good Die) 測(cè)試以及基板互連測(cè)試 [70]。由于芯粒種類繁多�����,不同芯粒可能采用不同的接口協(xié)議���、不同的 I/O 管腳速率約束以及不同的植球方式�����,需要對(duì)芯粒測(cè)試提供一個(gè)最大公約測(cè)試集���,基于該測(cè)試集標(biāo)準(zhǔn),所有的芯粒生產(chǎn)廠商均應(yīng)提供符合該標(biāo)準(zhǔn)的測(cè)試向量�。針對(duì)封裝互連的測(cè)試技術(shù),由于集成芯片中包含大量的芯粒間并行傳輸總線結(jié)構(gòu)�����,先進(jìn)封裝工藝的良率問(wèn)題可能導(dǎo)致某些互連總線發(fā)生橋接 / 短路故障�����,或者導(dǎo)致信號(hào)偏移率過(guò)大�,無(wú)法滿足高速數(shù)據(jù)傳輸?shù)臅r(shí)序要求���。集成芯片先進(jìn)封裝與傳統(tǒng) PCB 板級(jí)封裝有顯著區(qū)別���,一旦有互連線或互連部件發(fā)生故障,很難對(duì)其進(jìn)行替換�。因此需要研究并行傳輸總線結(jié)構(gòu)的可測(cè)性設(shè)計(jì)和互連線層面的冗余設(shè)計(jì)�,設(shè)計(jì)在線的互連線修復(fù)機(jī)制和數(shù)據(jù)傳輸協(xié)議修復(fù)機(jī)制。根據(jù)故障發(fā)生的模式�����,對(duì)數(shù)據(jù)發(fā)送和接收端口進(jìn)行動(dòng)態(tài)重配置�,保證接口功能和時(shí)序的正確性�。
圖 4.4 2.5D 芯粒結(jié)構(gòu)示意圖
圖 4.4 針對(duì)集成芯片的可測(cè)性���,需要研究可測(cè)性設(shè)計(jì)結(jié)構(gòu)將各個(gè)芯粒有效隔離�,以提升集成芯片的魯棒性。如果采用傳統(tǒng)芯片菊花鏈?zhǔn)降目蓽y(cè)性設(shè)計(jì)�,一旦其中一個(gè)芯粒發(fā)生故障,整個(gè)可測(cè)性設(shè)計(jì)結(jié)構(gòu)就無(wú)法正常工作���,也無(wú)法準(zhǔn)確定位缺陷位置���。為此需要將關(guān)鍵信號(hào)或者線網(wǎng)直接連接到凸植球,并通過(guò)基板連接到封裝的引腳���,便于對(duì)這些關(guān)鍵信號(hào)進(jìn)行測(cè)試和觀察。此外需要對(duì)傳統(tǒng)的可測(cè)性設(shè)計(jì)結(jié)構(gòu)進(jìn)行改進(jìn)���,增加芯粒級(jí)內(nèi)部信號(hào)狀態(tài)的可測(cè)性。例如對(duì)于時(shí)鐘和復(fù)位等信號(hào)�����,需要設(shè)置單獨(dú)的鎖相環(huán) DFT 結(jié)構(gòu)�����,使內(nèi)部寄存器狀態(tài)可以在單獨(dú)的鎖相環(huán)驅(qū)動(dòng)下進(jìn)行外部輸出�。需要配置專門的模擬信號(hào)監(jiān)測(cè)模塊�����,用于監(jiān)測(cè)各個(gè)芯粒內(nèi)部的供電噪聲和紋波�����。為了更有效地測(cè)試芯粒間互連故障�����,還需要研究類似 IEEE1149.1 標(biāo)準(zhǔn)的回環(huán)測(cè)試�,將互連總線兩端的芯粒進(jìn)行配對(duì)�����,形成回環(huán)�����,對(duì)數(shù)據(jù)發(fā)送端和接收端進(jìn)行單獨(dú)測(cè)試���,更有效地定位互連總線故障�。
在生產(chǎn)制造環(huán)節(jié)的測(cè)試之外���,針對(duì)集成芯片整個(gè)生命周期的工作狀態(tài)檢測(cè)和可靠性也是亟待解決的關(guān)鍵問(wèn)題���。需要研究集成芯片生命周期管理技術(shù),例如在芯粒內(nèi)部或基板上配置傳感器�,對(duì)器件參數(shù)偏移、供電電壓以及環(huán)境溫度進(jìn)行監(jiān)測(cè)�����,并根據(jù)芯粒的工況和老化情況進(jìn)行新的協(xié)議或時(shí)序配置�����,延長(zhǎng)集成芯片的使用壽命���。探索利用 DFT 中的冗余設(shè)計(jì)�,對(duì)某些芯粒或互連線老化效應(yīng)超過(guò)閾值的部分進(jìn)行替換或修復(fù)�����。
相比無(wú)源硅基板�,有源基板能夠?qū)崿F(xiàn)更高的靈活性和可擴(kuò)展性�。如何對(duì)基于有源基板的集成芯片進(jìn)行測(cè)試和可測(cè)性設(shè)計(jì)成為新的問(wèn)題�����。由傳統(tǒng)的 JTAG 測(cè)試結(jié)構(gòu)擴(kuò)展的 IJTAG 1687 可以用于有源基板集成芯片的層次化測(cè)試。通過(guò)對(duì) TAP 控制器的重配置�,可以將每個(gè)芯粒配置成旁路模式或者測(cè)試模式。根據(jù)測(cè)試時(shí)機(jī)不同�����,IJTAG 測(cè)試標(biāo)準(zhǔn)可以用于芯粒封裝前的綁定前測(cè)試�,封裝過(guò)程中的綁定中測(cè)試�����,以及封裝完成之后的綁定后測(cè)試���。
綜上所述,集成芯片的可測(cè)性和測(cè)試技術(shù)對(duì)提升集成芯片制造良率�、定位缺陷位置���、提升集成芯片可靠性具有重要意義���。需要研究面向集成芯片的最大公約芯粒測(cè)試集�、互連線冗余和協(xié)議修復(fù)機(jī)制、可測(cè)試性結(jié)構(gòu)設(shè)計(jì)�����、全生命周期管理���、有源硅基板測(cè)試等關(guān)鍵技術(shù),實(shí)現(xiàn)缺陷的快速檢測(cè)���、替換或修復(fù),提升集成芯片制造良率并降低制造成本�����。
5���、集成芯片的工藝原理
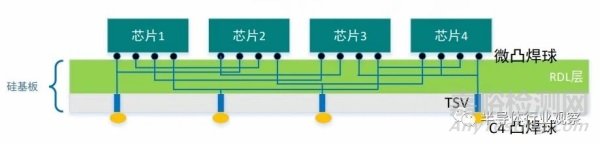
5.1 RDL/ 硅基板(Interposer)制造工藝
與傳統(tǒng)封裝基板(Substrate)級(jí) 2D 互聯(lián)相比,集成芯片工藝引入了銅互連工藝等芯片制造技術(shù),也因此形成了一些新形態(tài)�����,新功能的芯粒���。其中,最具有代表性的就是2.5D集成中硅基板(Interposer)���。圖 5.1 展示了利用硅通孔 (Through Silicon Via, TSV) 技術(shù)實(shí)現(xiàn)的,基于硅基板的 2.5D 封裝集成芯片結(jié)構(gòu)�。
圖 5.1 典型 3D 集成芯片結(jié)構(gòu)
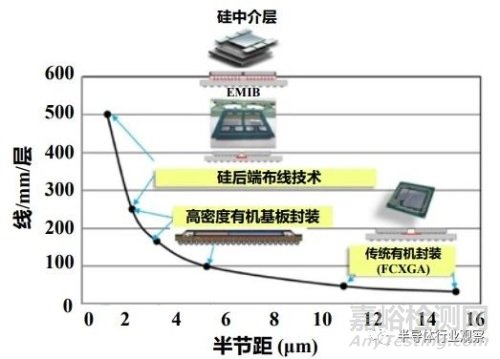
硅基板與上層芯粒�、底層封裝基板通過(guò)微凸點(diǎn)(Micro-bump)和 C4 凸點(diǎn)(C4 bump)實(shí)現(xiàn)電信號(hào)連接。Interposer 可以用于提高芯片的性能和帶寬���,使芯片更加緊湊。芯粒間的互連線是在硅基板上的多層銅互連金屬工藝實(shí)現(xiàn)���,因此可以實(shí)現(xiàn)微米級(jí)的間距布線�����。當(dāng)工藝設(shè)備受限時(shí)�����,也可以采用重分布層(Redistribution Layer,RDL)工藝取代銅互連工藝���,實(shí)現(xiàn)較高密度互連�����。硅通孔(TSV)是硅基板工藝相比一般 CMOS 芯片工藝新增的工藝。TSV 的制造工藝是通過(guò)激光鉆孔或深反應(yīng)離子刻蝕(Deep Reactive Ion Etching�,DRIE)在硅基片上形成垂直穿孔結(jié)構(gòu)。這些孔可穿透多個(gè)層次�,連接不同的電路層���,然后進(jìn)行襯底沉積(通常是一層絕緣材料���,如二氧化硅),以提供電隔離和機(jī)械支撐�。再通過(guò)物理蒸鍍或電化學(xué)填充等技術(shù),在 TSV 孔中沉積導(dǎo)電金屬(如銅)�����,以建立電連接���。最后,使用化學(xué)機(jī)械拋光(Chemical Mechanical Planarization�����,CMP)等技術(shù)���,將金屬填充的表面與基片表面平坦化,以便后道工續(xù)�����。由于 TSV 的深度一般小于硅片的厚度�,還要將硅基板減薄后才能將 TSV 露頭。為了保證高性能芯片的電源完整性�����,在硅基板中還會(huì)制造高深寬比�、高電容密度的的深槽電容(Deep Trench Capacitor,DTC)用于對(duì)電源的退耦�����。其原理是�����,在硅槽中一個(gè)頂部電極層和一個(gè)底部電極層之間填充電容高介電常數(shù)材料,通過(guò)將深溝槽(DT)蝕刻到硅襯底中而形成三維垂直電容器�。DTC 的電容密度為 300nF/mm2。不難發(fā)現(xiàn)�����,在 2.5D 集成芯片中���,硅基板的面積決定了集成芯片的面積。因此�����,突破硅基板的面積上限是一項(xiàng)重要的挑戰(zhàn)�。臺(tái)積電對(duì)未來(lái)的硅基板面積擴(kuò)大已制定了明確的技術(shù)規(guī)劃。一般地�,單芯片制造的最大面積上限由光刻機(jī)的光罩尺寸(reticle)決定�,如何實(shí)現(xiàn)超過(guò) 3-4 個(gè)光罩尺寸的硅基板是一項(xiàng)重要的課題。

圖 5.2 TSMC 對(duì)硅基板面積的技術(shù)路線圖
在大尺寸硅基板的制造上�����,仍然存在這多個(gè)科學(xué)問(wèn)題有待攻克�。最具代表性的翹曲與應(yīng)力建模�。由于 TSV 的深度一般小于硅片的厚度���,因此需要將硅基板減薄到 100 微米以下�,此時(shí)大面積硅基板易發(fā)生翹曲���,甚至斷裂。建立合理的應(yīng)力模型���,準(zhǔn)確預(yù)測(cè)在包含 TSV�����、DTC 等工藝后晶圓的翹曲程度將有助于突破硅基板的面積上限���。但這一模型的科學(xué)基礎(chǔ)需要力學(xué)、工程材料領(lǐng)域的交叉研究���。此外,多次曝光 / 拼接縫合(stiching)技術(shù)�、高密度高深寬比的 TSV 工藝也是硅基板制造中的難題�����。
5.2 高密度凸點(diǎn)鍵合和集成工藝
“一代芯片需要一代封裝”�����,目前半導(dǎo)體先進(jìn)制程紛紛邁入了 7nm�、5nm�����,開(kāi)始朝 3nm 和 2nm邁進(jìn)�,晶體管尺寸不斷接近物理極限,先進(jìn)制程的持續(xù)微縮難度越來(lái)越高���,迫切的需求刺激業(yè)界尋求新的解決方案,封裝集成的重要性不斷顯著�����。在集成芯片中���,互連密度已由傳統(tǒng)的百微米級(jí)節(jié)距演進(jìn)至微米級(jí)節(jié)距,并快速向亞微米級(jí)節(jié)距發(fā)展���。針對(duì)大規(guī)模芯粒及封裝結(jié)構(gòu)高度復(fù)雜���、高密度互連和超高密度鍵合,其封裝設(shè)計(jì)中缺陷預(yù)測(cè)與抑制難度激增�,亟需研究高密度高可靠凸點(diǎn)鍵合和集成工藝�。
圖 5.3 互連密度的演變 [72]
在三維空間內(nèi)�����,芯片 / 芯粒間互連可分為三類:(1)芯粒表面與外界的垂直互連通道,包括傳統(tǒng)的凸點(diǎn)���、微凸點(diǎn)和新興的混合鍵合互連界面;(2)芯粒間水平互連導(dǎo)線���,主要指基板或重布線層的導(dǎo)線陣列�����;(3)芯粒內(nèi)部的垂直通孔結(jié)構(gòu)���,即硅通孔���,主要實(shí)現(xiàn)多層芯粒堆疊中的互連。如圖 5.3所示���,隨著系統(tǒng)性能對(duì)互連密度要求的不斷提高,不僅傳統(tǒng)二維平面內(nèi)互連線節(jié)距不斷微縮�����,而且穿過(guò)芯粒內(nèi)部的硅通孔垂直連接也應(yīng)運(yùn)而生。三種互連共同組成了先進(jìn)封裝中的三維互連網(wǎng)絡(luò)�����。在快速發(fā)展的先進(jìn)封裝技術(shù)中�,上述三類互連結(jié)構(gòu)都在快速微縮�。后兩類互連,互連導(dǎo)線和硅通孔節(jié)距已經(jīng)進(jìn)入了 10 微米以下�。在第一類互連中���,傳統(tǒng)的凸點(diǎn)鍵合方式已逼近 10 微米的物理極限���。混合鍵合可有效突破 10 微米極限���,向亞微米級(jí)節(jié)距進(jìn)行快速微縮。當(dāng)前比利時(shí) imec 研究所已實(shí)現(xiàn) 0.8 微米混合鍵合技術(shù)的成功研發(fā)�����,美國(guó) Intel 公司已實(shí)現(xiàn)面向量產(chǎn)的 3 微米節(jié)距混合鍵合技術(shù)的驗(yàn)證。
混合鍵合技術(shù)是將兩片需要鍵合在一起的晶圓�����,各自完成制程最后一步的金屬連線層并實(shí)現(xiàn)熔合鍵合�����,此層上只有兩種材質(zhì):銅及介電質(zhì)�。與凸點(diǎn)鍵合相比���,混合鍵合具有結(jié)構(gòu)、材料上根本的革新�����,并帶來(lái)顯著的性能優(yōu)勢(shì):(1)采用內(nèi)嵌式超平表面銅接口�����,避免了鍵合對(duì)準(zhǔn)過(guò)程中接口倒塌變形、鍵合空洞及相應(yīng)失效風(fēng)險(xiǎn);(2)采用預(yù)填充式無(wú)機(jī)介電層�,相比于傳統(tǒng)有機(jī)底填料,顯著提高了熱穩(wěn)定性�����。因此�����,混合鍵合不僅可以支撐互連節(jié)距向亞微米節(jié)距持續(xù)微縮���,且對(duì)于封裝系統(tǒng)整體的電性能和熱機(jī)械性能具有顯著提升作用 [73]���。但是�����,實(shí)現(xiàn)混合鍵合對(duì)于工藝和材料提出了新的挑戰(zhàn),需要傳統(tǒng)的晶圓制造企業(yè)和封裝企業(yè)緊密協(xié)同���,研發(fā)新型專用工藝�����。挑戰(zhàn)包括:(1)從當(dāng)前芯片后道工藝(BEoL)大馬士革工藝出發(fā)�����,制造適合混合鍵合的頂部金屬 - 介電層�����,保證高鍵合強(qiáng)度�;(2)開(kāi)發(fā)面向混合鍵合的高精度高潔凈度劃片技術(shù)�����,保證鍵合前后芯片邊緣無(wú)崩邊�、隱裂���;(3)控制晶圓整體翹曲和表面平整度�����,實(shí)現(xiàn)整片晶圓或芯片的無(wú)空洞完整鍵合�。
高密度凸點(diǎn)鍵合和集成工藝是在系統(tǒng)集成密度�����、系統(tǒng)的復(fù)雜程度以及元件的集成度提高需求下帶來(lái)的的先進(jìn)封裝技術(shù)需求�。其工藝相對(duì)簡(jiǎn)單�,集成密度高�����,能夠同時(shí)實(shí)現(xiàn)電學(xué)連接和物理支撐�,是集成芯片先進(jìn)封裝領(lǐng)域研究和發(fā)展的重點(diǎn)���。為了實(shí)現(xiàn)高密度凸點(diǎn)鍵合和集成工藝�����,仍然需要大量研究工作,包括優(yōu)化設(shè)計(jì)和工藝參數(shù)�����,提高晶圓對(duì)準(zhǔn)精度,實(shí)現(xiàn)低溫退火以及降低成本等���。隨著集成芯片的發(fā)展�,芯粒集成度(種類和數(shù)量)不斷提升的需求將進(jìn)一步推動(dòng)先進(jìn)封裝和集成工藝的發(fā)展���,進(jìn)一步縮小互連節(jié)距���,提升互連密度和互連帶寬�����。
5.3 基于半導(dǎo)體精密制造的散熱工藝
高性能�����、高集成度已成為現(xiàn)代電子芯片的發(fā)展趨勢(shì)�,超高功率芯粒的高密度異質(zhì)異構(gòu)集成將導(dǎo)致其熱耗和熱流密度急劇攀升���,給芯粒集成芯片熱管理提出了重大挑戰(zhàn)���。在高運(yùn)行溫度下,芯片內(nèi)各種輕微物理缺陷造成的故障更容易顯現(xiàn)出來(lái)�,高溫會(huì)使芯片內(nèi)延時(shí)增加,降低 CPU 的工作效率�����。同時(shí)�,隨著芯片溫度升高�����,芯片漏電流增大�����,由于 IR Drop 導(dǎo)致工作電壓降低,容易出現(xiàn)可靠性降低甚至失效的問(wèn)題�����。
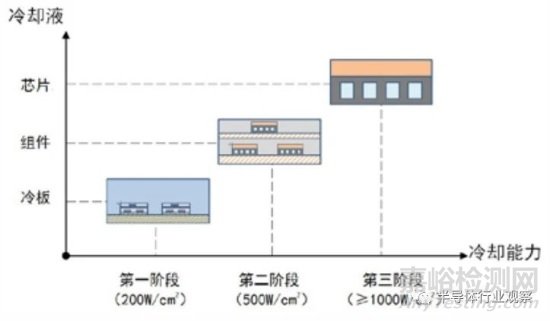
芯片熱管理技術(shù)路線主要可分為以下三個(gè)階段 [75](如圖 5.4 所示):第一階段主要采用逐層散熱的方法�����,芯片封裝外殼下方是基板�����,基板下方布置微通道熱沉冷板�����,各界面間涂覆熱界面材料�,散熱能力可達(dá) 200 W/cm²���。第二階段將組件殼體集成于流道側(cè)面�����,冷卻液直接進(jìn)入組件殼體���,傳熱路徑為芯片→熱沉→組件殼體�����,減少了傳熱環(huán)節(jié)�����,消除了組件與冷板之間的接觸熱阻和冷板熱阻,熱流密度可提升至 500 W/cm²�。第三階段���,近結(jié)點(diǎn)冷卻技術(shù)�,它采用高效對(duì)流 - 蒸發(fā)傳熱特性的微通道直接集成到基底材料內(nèi)部或非?����?拷l(fā)熱元件以實(shí)現(xiàn)高效散熱,并集成微泵�、微傳感器和微換熱器等微熱控元件,實(shí)現(xiàn)芯片一體化閉式廢熱排散的冷卻循環(huán)�����,如圖 5.5 所示�。近結(jié)點(diǎn)冷卻通過(guò)引入微納工藝�,大幅減小了散熱過(guò)程中的傳熱路徑和環(huán)節(jié),散熱能力可達(dá) 1000 W/cm²以上 [76][77]�。
圖 5.4 芯片熱管理技術(shù)分類 [75]
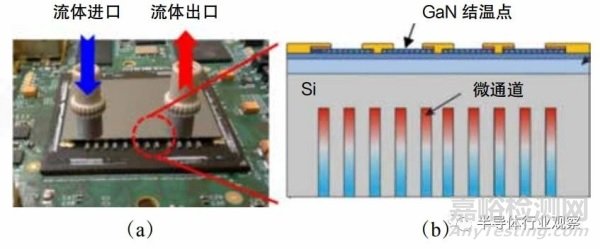
集成芯片的功率未來(lái)將達(dá)到數(shù) kW 甚至十幾 kW,芯片熱流密度將超過(guò)數(shù)百 W/cm²�����,芯片熱點(diǎn)的熱流密度將突破 kW/cm²量級(jí)�����。近結(jié)點(diǎn)微通道散熱技術(shù)將是重要的技術(shù)發(fā)展方向�,不僅可以實(shí)現(xiàn)高熱流密度芯片的高效散熱�,突破芯片熱耗墻,同時(shí)還可以將熱管理系統(tǒng)微型化�,集成到芯粒芯片中���,大幅提升芯片集成化程度���。在工藝實(shí)現(xiàn)上,目前微通道散熱技術(shù)主要有兩種方案�����,如圖 5.5 所示:圖 5.5(a)給出了轉(zhuǎn)接板集成微通道的近結(jié)點(diǎn)微通道散熱系統(tǒng)架構(gòu)���,圖 5.5(b)給出了晶圓級(jí)集成微通道的近結(jié)點(diǎn)微通道散熱系統(tǒng)架構(gòu)�����。轉(zhuǎn)接板集成微通道的散熱架構(gòu)集成封裝更為簡(jiǎn)單�����,無(wú)需對(duì) Die( 裸片 )進(jìn)行調(diào)整,但是其散熱性能相對(duì)有限�����;而晶圓級(jí)集成微通道的近結(jié)點(diǎn)散熱系統(tǒng)架構(gòu)�,冷卻工質(zhì)直接引入到 Die 的背面���,散熱通道與熱源的距離從 mm 級(jí)縮小至 μm 級(jí),散熱性能極大提升�,但是其集成封裝較為復(fù)雜,需要在 Die 設(shè)計(jì)時(shí)就要考慮微流道結(jié)構(gòu)設(shè)計(jì)�。
圖 5.5 近結(jié)點(diǎn)微通道冷卻技術(shù) [76][77]
與傳統(tǒng)的熱沉冷板技術(shù)相比,上述兩種技術(shù)架構(gòu)不僅需要綜合考慮材料的導(dǎo)熱能力���、熱膨脹特性、電學(xué)特性和材料的加工制造能力等因素���,以實(shí)現(xiàn)流-固-熱-力-電的良好兼容���,而且芯片上元件眾多,材料屬性差異顯著�����,往往還需在芯片級(jí)集成微閥�、連接管道等部件�,三維堆疊芯片內(nèi)的流體與電學(xué)連接更加復(fù)雜,亟待突破近結(jié)點(diǎn)微通道設(shè)計(jì)優(yōu)化與強(qiáng)化換熱方法�、多層異質(zhì)界面封裝集成方法���、芯粒集成芯片熱 - 電 - 力 - 流一體化協(xié)同設(shè)計(jì)等關(guān)鍵技術(shù)�����。
6�、白皮書(shū)觀點(diǎn):集成芯片的機(jī)遇與挑戰(zhàn)
6.1從堆疊法到構(gòu)造法的集成芯片���,是符合我國(guó)國(guó)情和產(chǎn)業(yè)現(xiàn)狀的一條現(xiàn)實(shí)發(fā)展道路
在摩爾定律尺寸微縮的經(jīng)典路徑指導(dǎo)下���,當(dāng)前集成電路設(shè)計(jì)采用自下而上的堆疊法�����,核心是基礎(chǔ)器件與制造工藝�。如圖 6.1,芯片設(shè)計(jì)是基于 EDA 工具�����,將器件集成到電路,再發(fā)展到完整芯片的過(guò)程���。隨著經(jīng)典摩爾定律的發(fā)展路徑���,芯片規(guī)模和集成度不斷提升,工藝主導(dǎo)的行業(yè)局面越來(lái)越凸顯,國(guó)外持續(xù)向“尺寸微縮”注力���,為延續(xù)光刻機(jī)���、EDA 等關(guān)鍵瓶頸提供技術(shù)保障,以此來(lái)控制整個(gè)產(chǎn)業(yè)鏈�����。因此�,國(guó)外集成芯片發(fā)展路徑�,仍然是一條工藝為主、集成為輔的發(fā)展路徑���。例如蘋果最新的M1 Ultra 芯片�����,利用 5nm 的先進(jìn)制造技術(shù),進(jìn)行了兩個(gè)芯粒的集成�����,促成了高性能新產(chǎn)品的發(fā)布。
圖 6.1 集成芯片設(shè)計(jì)路線:從堆疊法到構(gòu)造法
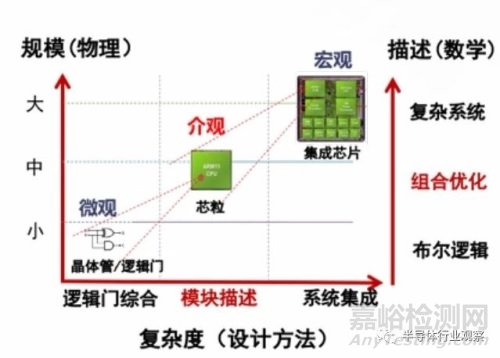
與自下而上的堆疊法不同�����,集成芯片采用自上而下的構(gòu)造法這一可行的發(fā)展路線�����。面向集成度進(jìn)一步提升的集成芯片設(shè)計(jì)�,構(gòu)造法從整體系統(tǒng)的角度出發(fā)�����,自上而下研究芯粒的分解與組合優(yōu)化理論�。為了對(duì)應(yīng)芯粒構(gòu)件這一新層次,如圖 6.2 所示�。參考物理�、化學(xué)、生物等學(xué)科�����,除了微觀���、宏觀理論,也部署了介觀理論���。介觀理論對(duì)集成芯片的構(gòu)造法研究具有重要意義���。芯片的介觀形態(tài)是區(qū)別于微觀的晶體管 / 基礎(chǔ)部件、宏觀的集成芯片 / 系統(tǒng)芯片的中間形態(tài)���,介觀更多表現(xiàn)在芯粒、IP 層次���。從功能描述來(lái)看�����,微觀的布爾邏輯�、宏觀的復(fù)雜系統(tǒng)都已經(jīng)有扎實(shí)的數(shù)學(xué)基礎(chǔ)和物理描述�����;從設(shè)計(jì)方法學(xué)角度來(lái)看���,邏輯門綜合�����、高層次系統(tǒng)綜合已能對(duì)芯片的微觀和宏觀進(jìn)行描述�。而在芯片介觀形態(tài)和構(gòu)造上�,都缺乏相應(yīng)的數(shù)學(xué)、物理基礎(chǔ)�����,在設(shè)計(jì)方法學(xué)�、體系結(jié)構(gòu)以及制造工藝等都存在科學(xué)與技術(shù)挑戰(zhàn)���。自上而下的構(gòu)造法能夠通過(guò)介觀芯粒解耦�,實(shí)現(xiàn)應(yīng)用 - 集成 - 設(shè)計(jì) - 工藝協(xié)同�����,從系統(tǒng)和應(yīng)用需求出發(fā)�,依靠自上而下的方法學(xué),可以發(fā)展出費(fèi)效比低的系統(tǒng)�����。
圖 6.2 集成芯片的介觀理論
采用構(gòu)造法設(shè)計(jì)集成芯片是符合我國(guó)國(guó)情和當(dāng)前產(chǎn)業(yè)現(xiàn)狀的一條現(xiàn)實(shí)發(fā)展道路�����。從中短期來(lái)看�,中國(guó)集成電路產(chǎn)業(yè)無(wú)法在短時(shí)間內(nèi)破解 EUV 光刻機(jī)瓶頸�,實(shí)現(xiàn) 7nm 以下自主制造工藝難度很大�����。我國(guó)的產(chǎn)業(yè)優(yōu)勢(shì)在于龐大的市場(chǎng)規(guī)模�����,集成芯片技術(shù)可以基本滿足我國(guó)的中短期需求�����,并利用大規(guī)模的市場(chǎng)需求來(lái)刺激技術(shù)進(jìn)步�����,同時(shí)帶動(dòng)其它路徑發(fā)展�。市場(chǎng)規(guī)模龐大帶來(lái)的另外一個(gè)特點(diǎn)是應(yīng)用需求的種類多�����、碎片化�,傳統(tǒng)的芯片設(shè)計(jì)制造成本高,無(wú)法滿足種類繁多的應(yīng)用需求�。而集成芯片可以利用其模塊化的芯粒復(fù)用技術(shù)���,大幅降低成本�,從而滿足更多行業(yè)的芯片需求�。同時(shí),從整個(gè)集成電路的產(chǎn)業(yè)鏈來(lái)看���,我國(guó)在封裝測(cè)試環(huán)節(jié)占據(jù)一定的比例���,具有一定的產(chǎn)業(yè)優(yōu)勢(shì)。對(duì)我國(guó)而言�,依托龐大的市場(chǎng)需求和領(lǐng)先的先進(jìn)封裝產(chǎn)業(yè),以集成為主的構(gòu)造法方案可基于國(guó)內(nèi)現(xiàn)有產(chǎn)業(yè)鏈實(shí)現(xiàn)高性能芯片�,技術(shù)上可行且能解決當(dāng)下的市場(chǎng)需求。自上而下的構(gòu)造法是一條由系統(tǒng)和應(yīng)用主導(dǎo)產(chǎn)業(yè)發(fā)展的集成芯片發(fā)展新路徑�,符合我國(guó)國(guó)情和當(dāng)前產(chǎn)業(yè)特點(diǎn)。
6.2 集成芯片的三大科學(xué)問(wèn)題與十大技術(shù)難題
集成芯片的發(fā)展仍處于初級(jí)階段�,目前國(guó)內(nèi)外的商業(yè)化集成芯片產(chǎn)品普遍面臨集成度低的問(wèn)題�����,如芯粒數(shù)量一般少于 10 個(gè)�、芯粒種類少于 5 種�����,遠(yuǎn)遠(yuǎn)未能發(fā)揮該設(shè)計(jì)應(yīng)有的性能優(yōu)勢(shì)���。
我們認(rèn)為:集成芯片的集成度(種類和規(guī)模)的提升,是推動(dòng)集成芯片技術(shù)體系的主要驅(qū)動(dòng)力量�����。
集成度的大幅提升�,將引發(fā)從芯片設(shè)計(jì)方法學(xué)、體系結(jié)構(gòu)�����、仿真工具到底層工藝制備等一系列的科學(xué)問(wèn)題���。
科學(xué)問(wèn)題一:芯粒的數(shù)學(xué)描述和組合優(yōu)化理論。面向分解中的數(shù)學(xué)問(wèn)題�����,目的是解決如何將復(fù)雜的功能需求�����,分解并映射到大規(guī)模的芯粒構(gòu)件上�����。在少量芯粒集成時(shí)�����,映射關(guān)系較為簡(jiǎn)潔�����,而將復(fù)雜功能分解到大量芯粒時(shí)�����,則需要借助數(shù)學(xué)運(yùn)算來(lái)完成和優(yōu)化�。傳統(tǒng)集成電路針對(duì)微觀晶體管的數(shù)學(xué)描述并不適用于芯粒尺度���,因此亟需建立新的數(shù)學(xué)理論。傳統(tǒng)集成電路設(shè)計(jì)依靠的布爾代數(shù)�����、符號(hào)邏輯等方法�����,不適用于介觀尺度的芯粒功能分解���。這一理論不是簡(jiǎn)單的 Top-Down 的宏觀系統(tǒng)拆分方法的遷移,需要探究應(yīng)用場(chǎng)景下芯粒的抽象表達(dá)���,為大規(guī)模集成芯片的分解提供理論基礎(chǔ)���。
科學(xué)問(wèn)題二:大規(guī)模芯粒并行架構(gòu)和設(shè)計(jì)自動(dòng)化。面向芯粒組合并行挑戰(zhàn)的信息科學(xué)問(wèn)題�,解決隨著芯粒的數(shù)量和種類大幅提升,怎樣應(yīng)對(duì)芯片設(shè)計(jì)復(fù)雜度的爆炸式增長(zhǎng)問(wèn)題�����。需要設(shè)計(jì)超越多核架構(gòu)的高并行效率新架構(gòu)���,充分釋放芯粒組合并行的算力潛能,破解阿梅達(dá)爾定律和計(jì)算 - 通信屋頂曲線模型等帶來(lái)的擴(kuò)展性和并行極限難題���。另一方面�����,少量芯粒集成時(shí)由于涉及的芯粒種類少、復(fù)用率低�、空間維度小,現(xiàn)有 EDA 工具主要用于以晶體管為單元的二維電路設(shè)計(jì)�,無(wú)法輔助以芯粒為單元的三維布局開(kāi)發(fā)�。因此需要突破芯粒層面的設(shè)計(jì)語(yǔ)言和綜合問(wèn)題�,探索新布局布線方法�����,形成集成芯片 EDA 新工具�����,大幅降低集成芯片設(shè)計(jì)周期�。
科學(xué)問(wèn)題三:芯粒尺度的熱力電多場(chǎng)耦合機(jī)制與界面理論�����。面向集成挑戰(zhàn)的物理科學(xué)問(wèn)題�,目的是解決不同功能和種類的芯粒在形成界面時(shí)���,如何優(yōu)化熱�、電傳導(dǎo)���,避免應(yīng)力破壞等問(wèn)題�����。大規(guī)模芯粒集成將擴(kuò)展到三維空間���,多層堆疊結(jié)構(gòu)帶來(lái)了復(fù)雜界面的物理量傳導(dǎo)耦合問(wèn)題。集成芯片需要準(zhǔn)確預(yù)測(cè)系統(tǒng)在多物理場(chǎng)中運(yùn)行狀態(tài)�,特別是電磁場(chǎng)、熱和應(yīng)力翹曲�,并在跨尺度下形成較為完整的研究體系�。然而,現(xiàn)有的宏觀結(jié)構(gòu)力學(xué)�����、工程熱學(xué)與量子器件的微觀表面力學(xué)等理論缺乏深層次耦合交互�����。以熱仿真為例���,微觀層面上在器件、量子尺度的熱仿真理論采用波爾茨曼輸運(yùn)理論等�����,宏觀層面上在大封裝尺度的熱理論采用熱傳導(dǎo)、擴(kuò)散方程等���,在芯粒尺度的熱界面理論不完善�;在集成芯片須明晰多芯粒系統(tǒng)中的電磁���、熱和應(yīng)力的相互作用,探索跨尺度的多物理場(chǎng)交互的仿真方法與工具���。
在以上集成芯片的科學(xué)問(wèn)題基礎(chǔ)上�����,集成芯片前沿技術(shù)科學(xué)基礎(chǔ)專家組進(jìn)一步提出十大技術(shù)難題(2023 版),見(jiàn)下圖���,希望這些問(wèn)題能為集成芯片的發(fā)展起到牽引作用。
圖 6.3 集成芯片十大技術(shù)難題
7�����、參考文獻(xiàn)