一����、研究背景與意義
在工業(yè)4.0時代,高端復雜設備向智能化����、系統(tǒng)化快速演進,其運行安全性與可靠性成為工業(yè)生產(chǎn)的核心訴求�����。設備在長期運行中,受磨損���、隨機沖擊�����、負載變化等惡劣工況影響�,性能會逐漸退化�,甚至引發(fā)嚴重安全事故。故障預測與健康管理(PHM)技術應運而生�,其中設備剩余壽命(RUL)預測是PHM的核心環(huán)節(jié),可為維修決策提供關鍵依據(jù)���,對保障設備安全運行�����、降低運維成本具有重要意義。
傳統(tǒng)基于深度學習的RUL預測方法多依賴監(jiān)督學習框架�����,需大量含完整壽命標簽的“理想數(shù)據(jù)”訓練模型。然而��,實際工業(yè)場景中��,完整壽命周期數(shù)據(jù)稀缺�,大量存在的是片段式、無完整標簽的“非理想數(shù)據(jù)”����。這種數(shù)據(jù)特性導致傳統(tǒng)模型泛化性弱、預測精度低�����。此外��,現(xiàn)有時序模型存在兩大局限:一是對高頻噪聲敏感�,易導致預測波動;二是基于循環(huán)神經(jīng)網(wǎng)絡(RNN)的模型采用順序計算�����,效率低且難以捕捉長時程特征���。因此�����,開發(fā)能有效利用非理想數(shù)據(jù)的高效RUL預測方法成為工業(yè)界與學術界的迫切需求����。
二、主要研究內(nèi)容
本文提出一種時序對比注意力網(wǎng)絡(SCAN)��,通過時序對比學習與注意力機制的深度融合���,實現(xiàn)非理想數(shù)據(jù)下的設備剩余壽命精準預測���。研究內(nèi)容主要包括模型架構設計、訓練策略優(yōu)化及多場景實驗驗證三部分���。
(一)模型整體架構
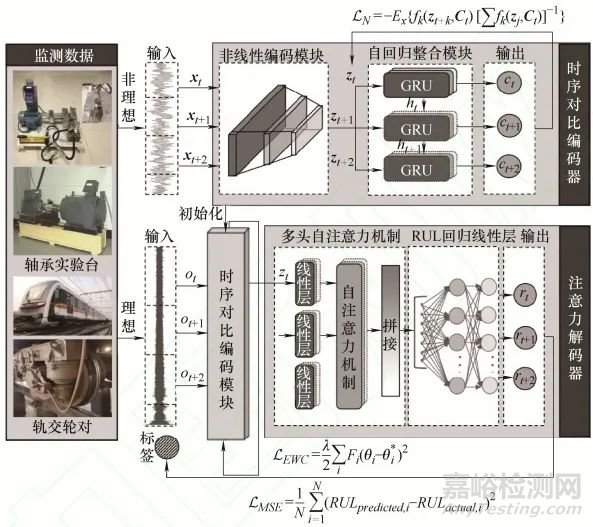
SCAN模型采用“編碼-解碼”雙階段架構���,核心由時序對比編碼器與壽命預測注意力解碼器組成。編碼器負責從非理想數(shù)據(jù)中提取深層退化特征��,無需依賴壽命標簽���;解碼器基于編碼特征實現(xiàn)RUL預測�����,通過注意力機制捕捉時序依賴��。兩者通過彈性權重共享策略實現(xiàn)協(xié)同優(yōu)化���,形成端到端的預測框架。
(二)時序對比編碼器設計
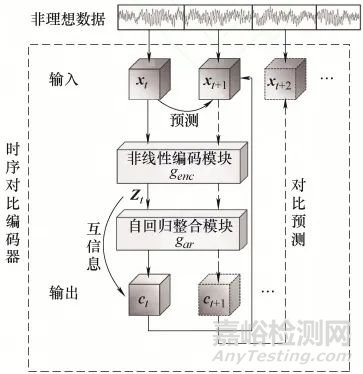
編碼器旨在無標簽條件下提取設備退化的時序特征��,由非線性編碼模塊與自回歸整合模塊構成��。
非線性編碼模塊基于卷積神經(jīng)網(wǎng)絡(CNN)構建�,包含多個卷積層、批標準化層與ReLU激活函數(shù)���。其功能是將原始監(jiān)測數(shù)據(jù)(如振動信號����、磨損參數(shù))映射為高維隱變量���,捕捉局部退化特征��。通過卷積操作的局部感受野特性����,有效過濾高頻噪聲,增強特征的魯棒性�����。
自回歸整合模塊基于門控循環(huán)單元(GRU)設計�,整合歷史隱變量序列,生成含長時程時序信息的退化特征向量�����。GRU通過重置門與更新門動態(tài)控制信息傳遞���,既能保留關鍵歷史信息�����,又能遺忘冗余噪聲��,解決傳統(tǒng)RNN的梯度消失問題��,更精準地刻畫設備性能隨時間的退化趨勢�����。
編碼器的訓練通過“對比預測任務”實現(xiàn):利用當前時刻的特征向量預測未來k步的隱變量��,通過噪聲對比估計損失函數(shù)優(yōu)化模型�。該過程強化了特征的時序自相關性���,使模型無需壽命標簽即可學習設備退化規(guī)律����。
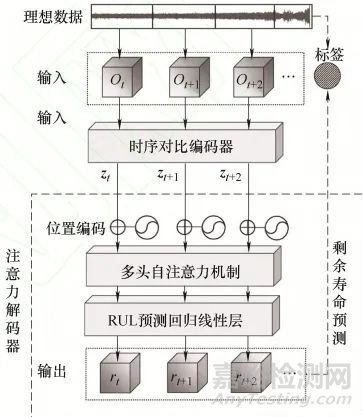
解碼器負責將編碼后的退化特征映射為RUL預測值��,核心是多頭自注意力機制��,解決傳統(tǒng)時序模型的效率與長依賴捕捉問題��。
為彌補自注意力機制對時序順序不敏感的缺陷���,解碼器首先引入位置編碼���,通過正弦余弦函數(shù)組合為每個時間步嵌入位置信息,確保模型理解時序先后關系��。
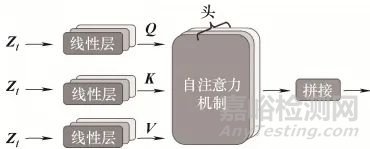
多頭自注意力機制將特征向量映射為查詢(Q)、鍵(K)����、值(V)矩陣,通過計算Q與K的相似度得到注意力分數(shù)���,再與V加權求和生成輸出���。“多頭”設計使模型能并行學習不同子空間的時序依賴,增強對復雜退化模式的建模能力����。相較于RNN的順序計算,自注意力機制支持并行處理���,大幅提升計算效率��,同時通過全局依賴建模��,捕捉長時程退化特征���。
解碼器末端通過線性層整合注意力特征,輸出最終RUL預測值�,實現(xiàn)從特征到預測結果的映射���。
為解決編碼器與解碼器的協(xié)同優(yōu)化問題,本文提出基于彈性權重共享(EWC)的訓練模式�����,分三階段實現(xiàn)模型優(yōu)化���。
第一階段,用非理想數(shù)據(jù)預訓練編碼器���,通過對比預測損失函數(shù)優(yōu)化參數(shù)�����,保存預訓練模型�,使其具備獨立提取退化特征的能力���。
第二階段���,將預訓練編碼器作為解碼器的前置模塊,引入EWC策略微調(diào)編碼器參數(shù)����。通過計算編碼器參數(shù)的費希爾信息�,衡量參數(shù)對特征提取的重要性:對關鍵參數(shù)施加強約束����,避免其在解碼器訓練中被過度修改;對次要參數(shù)放松約束��,使其適應預測任務��。這種差異化約束保障了編碼器特征提取能力的穩(wěn)定性����。
第三階段,用少量含標簽的理想數(shù)據(jù)訓練解碼器��,以均方誤差(MSE)為損失函數(shù)�,優(yōu)化解碼器參數(shù)的同時,通過EWC約束同步微調(diào)編碼器�����,實現(xiàn)兩者的高效協(xié)同�。
(五)實驗驗證設計
為驗證方法有效性,實驗選取兩類典型工業(yè)設備場景:軸承與城軌列車輪對���,采用公開與實際數(shù)據(jù)集開展驗證���。
軸承數(shù)據(jù)集包括XJTU-SY全壽命數(shù)據(jù)集與CWRU非完整壽命數(shù)據(jù)集�����,涵蓋不同轉速���、負載下的外圈、內(nèi)圈���、保持架故障樣本;輪對數(shù)據(jù)集來自5列城軌列車�,含不圓度、輪緣高度等磨損參數(shù)��,具有采樣間隔不均����、參數(shù)趨勢不一致的非理想特性。
實驗采用滑動窗口分段與正則化預處理數(shù)據(jù)�,以均方根誤差(RMSE)為評估指標,將SCAN與雙向LSTM��、GCU-Transformer、多尺度CNN等主流方法對比�����,并通過消融實驗驗證各模塊作用��。
三��、關鍵技術解析
(一)非理想數(shù)據(jù)的特征提取技術
針對非理想數(shù)據(jù)(片段化����、無標簽)的特性,時序對比編碼器通過“無監(jiān)督特征學習+時序建模”雙機制實現(xiàn)有效特征提取��。
非線性編碼模塊利用CNN的局部感知能力�����,對原始信號進行多層卷積與激活��,過濾高頻噪聲與無關干擾�����,提取局部退化特征(如振動信號中的沖擊成分、磨損參數(shù)的微小變化)���。批標準化層穩(wěn)定訓練過程���,ReLU激活函數(shù)引入非線性,增強特征表達能力���。
自回歸整合模塊通過GRU的門控機制����,將局部特征按時間序列整合�����,形成含長時程信息的退化特征向量��。例如�,在軸承退化過程中�����,早期振動信號變化微弱�,GRU可累積多時刻的微小變化,捕捉性能緩慢退化的趨勢;后期信號突變時�����,又能快速更新狀態(tài)�����,反映加速退化階段的特征���。
對比預測訓練通過“預測未來特征”任務,迫使模型學習時序相關性:若當前特征與未來特征關聯(lián)緊密(如退化趨勢一致)����,模型預測誤差小�;反之誤差大。這種機制使模型無需壽命標簽����,即可自主學習設備從健康到失效的退化規(guī)律。
(二)時序依賴建模與并行計算技術
壽命預測注意力解碼器通過多頭自注意力機制���,解決傳統(tǒng)時序模型的長依賴捕捉與計算效率問題�����。
位置編碼為每個時間步嵌入獨特的位置信息��,使模型能區(qū)分“早期-中期-晚期”的時序順序,例如在輪對磨損數(shù)據(jù)中���,即使某兩天的磨損值相同,模型也能通過位置編碼識別其處于退化前期還是后期����。
多頭自注意力機制通過多組Q�����、K�、V矩陣并行計算注意力�����,每組專注于不同的時序關系�。例如,一組可能關注相鄰時刻的短期變化(如每日磨損增量)����,另一組關注跨周/月的長期趨勢(如磨損速率的季節(jié)性波動)。通過拼接多組結果�����,模型可全面捕捉復雜的時序依賴���。
并行計算特性使注意力機制無需像RNN那樣按時間步順序處理數(shù)據(jù)��,而是一次性計算所有時刻的關聯(lián)�,大幅提升效率�。實驗顯示����,自注意力解碼器的迭代速度比GRU快45%,比LSTM快31%��,尤其適用于大規(guī)模工業(yè)監(jiān)測數(shù)據(jù)���。
(三)編碼-解碼協(xié)同優(yōu)化技術
彈性權重共享(EWC)策略通過差異化約束參數(shù)�����,實現(xiàn)編碼器與解碼器的有機協(xié)同���。
費希爾信息量化了編碼器參數(shù)對特征提取的重要性:例如����,卷積層中負責捕捉振動信號特定頻率成分的參數(shù)����,對退化特征提取至關重要,其費希爾信息值高�����,EWC對其施加強約束�,確保微調(diào)時不丟失關鍵特征提取能力;而某些輔助參數(shù)的費希爾信息值低��,允許較大調(diào)整以適應預測任務��。
這種機制平衡了“保留編碼器能力”與“適配解碼任務”的矛盾:編碼器預訓練獲得的非理想數(shù)據(jù)特征提取能力被保留�,解碼器則通過少量標簽數(shù)據(jù)學習如何將這些特征映射為RUL,實現(xiàn)“無監(jiān)督特征學習+有監(jiān)督預測”的高效結合���。
四�、創(chuàng)新點提煉
(一)理論框架創(chuàng)新:時序對比學習與注意力機制的深度融合
突破傳統(tǒng)監(jiān)督學習對理想數(shù)據(jù)的依賴�,提出“時序對比學習+注意力機制”的聯(lián)合框架,首次將時序對比學習范式應用于非理想數(shù)據(jù)的RUL預測����。
時序對比學習通過無監(jiān)督方式從非理想數(shù)據(jù)中挖掘退化規(guī)律,解決標簽稀缺問題����;注意力機制通過并行計算與全局依賴建模,提升預測效率與精度���。兩者結合形成“特征提取-時序建模-預測輸出”的端到端解決方案�����,為非理想數(shù)據(jù)場景下的壽命預測提供了新范式����。
(二)技術方法創(chuàng)新:非理想數(shù)據(jù)的無監(jiān)督特征學習機制
設計時序對比編碼器�����,實現(xiàn)無需壽命標簽的退化特征提取。傳統(tǒng)方法需完整壽命數(shù)據(jù)標注退化階段�����,而本方法通過“預測未來特征”的自監(jiān)督任務����,使模型自主學習時序相關性,例如在無標簽的軸承振動片段中�,可自動識別“輕微磨損-中度磨損-嚴重磨損”的特征差異。
這種機制不僅降低了對數(shù)據(jù)標注的依賴�,還能利用海量非理想數(shù)據(jù)(如設備日常運行的片段監(jiān)測數(shù)據(jù)),提升模型的泛化能力�����,尤其適用于難以獲取全壽命數(shù)據(jù)的高端設備(如軌交列車輪對)����。
(三)模型設計創(chuàng)新:高效時序依賴建模的注意力解碼器
針對傳統(tǒng)RNN順序計算效率低、長依賴捕捉弱的問題����,設計基于多頭自注意力的解碼器:
1. 多頭子空間并行學習,可同時捕捉短期波動與長期趨勢��,例如在輪對數(shù)據(jù)中,既能關注每日磨損的微小變化�����,又能捕捉月度磨損速率的變化規(guī)律���;
2. 并行計算架構大幅提升效率,解決工業(yè)大數(shù)據(jù)實時預測的時效性需求��;
3. 動態(tài)權重分配使模型聚焦關鍵退化階段�����,例如在軸承失效前的加速退化期�����,注意力分數(shù)自動提高���,增強對故障預警的敏感性��。
(四)訓練策略創(chuàng)新:彈性權重共享的協(xié)同優(yōu)化模式
提出EWC策略�,通過量化參數(shù)重要性實現(xiàn)編碼器與解碼器的協(xié)同優(yōu)化���。傳統(tǒng)聯(lián)合訓練易導致“災難性遺忘”(解碼器訓練破壞編碼器已學能力)���,而EWC對關鍵參數(shù)施加保護�,次要參數(shù)靈活調(diào)整�,例如在軸承與輪對跨場景遷移時,編碼器中通用的退化特征提取參數(shù)被保留�����,與設備相關的特異性參數(shù)被調(diào)整����,平衡了模型的通用性與場景適配性。
五�、實驗結果與分析
(一)軸承剩余壽命預測實驗
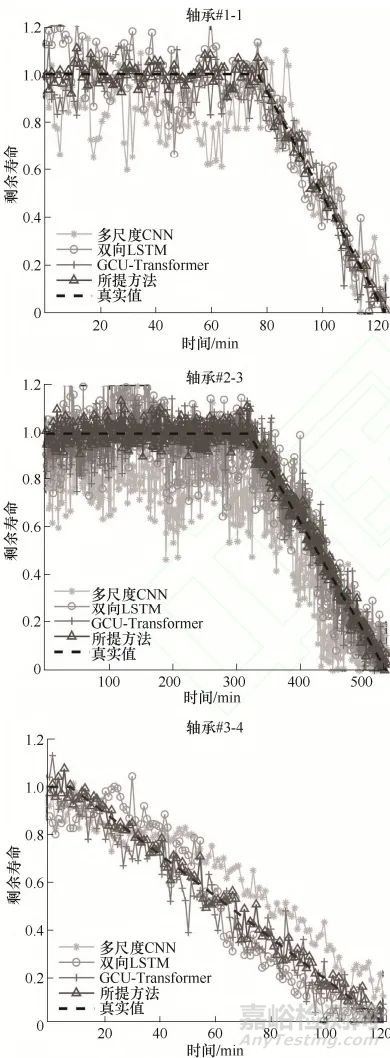
采用XJTU-SY與CWRU數(shù)據(jù)集,將SCAN與雙向LSTM��、GCU-Transformer����、多尺度CNN對比,結果顯示:
SCAN的平均RMSE為0.0686����,較最優(yōu)對比方法(GCU-Transformer)降低34%���。在#1-1、#2-3等典型樣本中�,SCAN的預測曲線更貼近真實值,尤其在退化加速階段�����,對故障的敏感性更高�����。
消融實驗驗證:含時序對比編碼器的模型預測曲線振蕩幅度降低40%�,表明其有效過濾高頻噪聲���;自注意力解碼器的迭代速度(201.77s/次)顯著快于GRU(368.46s/次)與LSTM(293.97s/次)�,驗證了并行計算的效率優(yōu)勢�����。
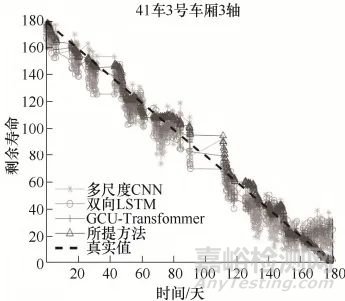
(二)城軌列車輪對剩余壽命預測實驗
基于5列列車的輪對磨損數(shù)據(jù)集�����,SCAN的平均RMSE為6.4371,除038號列車外均優(yōu)于對比方法���。輪對退化過程較平穩(wěn)��,SCAN仍能精準捕捉磨損趨勢�,例如在39車1號車廂2軸樣本中��,對輪緣厚度的緩慢退化預測誤差比GCU-Transformer降低18%�����。
結果表明����,SCAN不僅適用于軸承這類退化特征復雜的場景,也能有效處理輪對這類平穩(wěn)退化過程���,體現(xiàn)了良好的泛化能力�����。
(三)綜合分析
兩類場景的實驗均表明����,SCAN在非理想數(shù)據(jù)下的預測精度、穩(wěn)定性與效率均優(yōu)于主流方法��,平均精度提升約34%��。其優(yōu)勢源于:
1. 時序對比編碼器充分利用非理想數(shù)據(jù)���,提取穩(wěn)健的退化特征��;
2. 注意力解碼器高效捕捉時序依賴����,提升預測精度與速度�����;
3. EWC策略保障模型協(xié)同優(yōu)化�,增強魯棒性����。
六、結論與展望
(一)研究結論
本文提出的SCAN模型通過時序對比學習與注意力機制的融合����,有效解決了非理想數(shù)據(jù)下設備剩余壽命預測的難題:
1. 時序對比編碼器實現(xiàn)無標簽特征提取�����,擺脫對理想數(shù)據(jù)的依賴�,適用于工業(yè)場景中標簽稀缺的現(xiàn)狀����;
2. 注意力解碼器通過多頭自注意力機制,兼顧長時程時序依賴捕捉與并行計算效率����,提升預測精度與速度;
3. 彈性權重共享策略實現(xiàn)編碼-解碼協(xié)同優(yōu)化�,增強模型魯棒性與泛化能力。 實驗驗證�,SCAN在軸承與輪對場景中平均預測精度提升34%,為工業(yè)設備PHM提供了高效可靠的技術方案�����。
(二)未來展望
1. 擴展數(shù)據(jù)集類型:將方法應用于航空發(fā)動機�����、風電設備等更多工業(yè)場景,驗證其普適性���;
2. 優(yōu)化時序對比任務:設計更貼合設備退化規(guī)律的對比策略��,如引入領域知識引導特征學習�����;
3. 輕量化模型設計:針對邊緣設備部署需求�����,壓縮模型參數(shù)����,在保持精度的同時降低計算成本���;
4. 融合多源數(shù)據(jù):結合振動、溫度��、壓力等多傳感器數(shù)據(jù)�����,進一步提升預測魯棒性。
SCAN方法為非理想數(shù)據(jù)下的壽命預測提供了新思路����,其核心技術可推廣至工業(yè)健康管理的其他領域,推動PHM技術在實際生產(chǎn)中的落地應用���。
參考文獻:非理想數(shù)據(jù)下基于時序對比注意力模型的壽命預測方法��,林天驕等�,機械工程學報