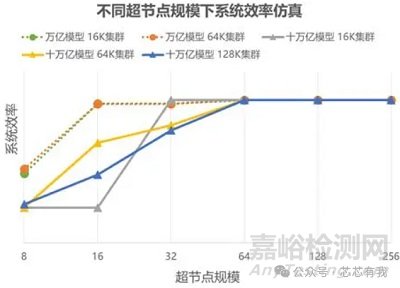
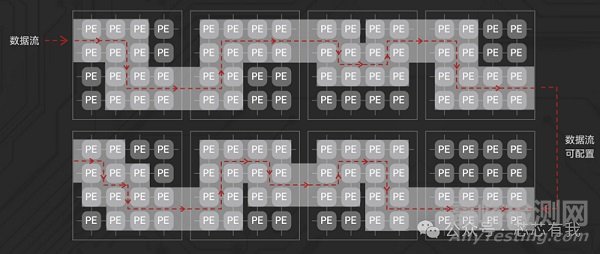
引言
隨著人工智能和高性能計(jì)算的快速發(fā)展�����,芯片架構(gòu)的創(chuàng)新成為推動(dòng)技術(shù)進(jìn)步的關(guān)鍵因素�����。華為超節(jié)點(diǎn)芯片架構(gòu)和Nvidia的算力芯片架構(gòu)是當(dāng)前業(yè)界的兩大重要技術(shù)方向��。本文將從架構(gòu)設(shè)計(jì)��、性能表現(xiàn)�����、應(yīng)用場(chǎng)景��、生態(tài)構(gòu)建等多個(gè)維度��,深入剖析華為超節(jié)點(diǎn)芯片架構(gòu)����,并與Nvidia算力芯片進(jìn)行對(duì)比分析�����,旨在為產(chǎn)業(yè)界提供一個(gè)全面��、客觀的參考。
1. 架構(gòu)設(shè)計(jì):華為超節(jié)點(diǎn)芯片與Nvidia算力芯片的底層邏輯
1.1 華為超節(jié)點(diǎn)芯片架構(gòu)
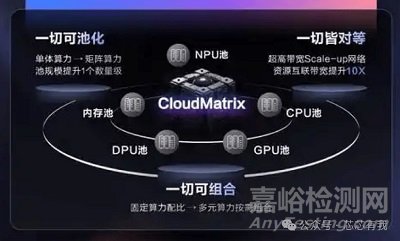
華為超節(jié)點(diǎn)芯片架構(gòu)是一種面向大規(guī)模并行計(jì)算的創(chuàng)新設(shè)計(jì)�����。其核心理念是通過(guò)高度集成的多核架構(gòu)和高效NoC�����,實(shí)現(xiàn)計(jì)算資源的高效利用和數(shù)據(jù)傳輸?shù)牡脱舆t���。具體而言�����,華為超節(jié)點(diǎn)芯片采用了以下3個(gè)核心關(guān)鍵技術(shù):
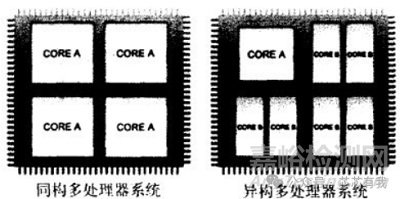
- 多核異構(gòu)設(shè)計(jì):集成多種類型的處理器核心��,包括通用CPU核心�、專用加速單元(如AI加速器)和FPGA模塊���,以滿足不同計(jì)算任務(wù)的需求�����。
解讀:多核異構(gòu)Multicore Heterogeneous
多核異構(gòu)通過(guò)結(jié)合不同類型的核心����,提供了一種高效和能效優(yōu)化的解決方案。常見的如ARM的big.LITTLE架構(gòu)��、NVIDIA的Tegra��、Qualcomm的Snapdragon
- Noc優(yōu)化:采用多級(jí)片上網(wǎng)絡(luò)架構(gòu)���,支持高帶寬�����、低延遲的數(shù)據(jù)傳輸�����,減少核心之間的通信瓶頸�����。
- 內(nèi)存層次優(yōu)化:結(jié)合片上緩存和HBM�����,優(yōu)化數(shù)據(jù)存儲(chǔ)和訪問(wèn)效率�。
1.2 Nvidia算力芯片架構(gòu)
Nvidia的算力芯片架構(gòu)主要圍繞其GPU技術(shù)展開,強(qiáng)調(diào)并行計(jì)算能力和圖形處理能力���。其核心架構(gòu)包括:
- CUDA:通過(guò)CUDA編程模型,Nvidia的GPU能夠高效處理大規(guī)模并行計(jì)算任務(wù)���。
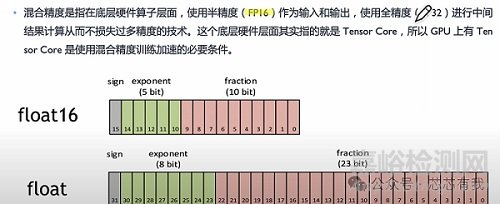
- Tensor Core:針對(duì)Deep Learning���,Nvidia引入了Tensor Core技術(shù),顯著提升了矩陣運(yùn)算效率�。
Tensor Core 的核心是它能夠處理混合精度計(jì)算。它是 NVIDIA GPU 的一個(gè)強(qiáng)大組件�����,它通過(guò)混合精度計(jì)算為 AI 和 HPC 應(yīng)用提供了前所未有的加速能力�。
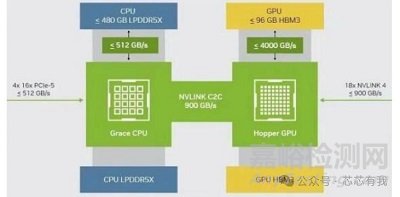
- HBM和GDDR:采用HBM技術(shù),確保數(shù)據(jù)傳輸?shù)母咝浴?/span>
2. 性能表現(xiàn):性能指標(biāo)的全方位對(duì)比
2.1 計(jì)算性能
- 華為超節(jié)點(diǎn)芯片:在多核異構(gòu)設(shè)計(jì)的支持下����,華為超節(jié)點(diǎn)芯片能夠靈活應(yīng)對(duì)多種計(jì)算任務(wù)����,其綜合計(jì)算性能在某些特定應(yīng)用場(chǎng)景下優(yōu)于傳統(tǒng)GPU����。例如,在AI推理任務(wù)中��,華為的昇騰910芯片能夠達(dá)到256 TOPS的算力�����。
- Nvidia算力芯片:Nvidia的GPU在圖形處理和深度學(xué)習(xí)任務(wù)中表現(xiàn)出色�����,尤其是在大規(guī)模并行計(jì)算任務(wù)中��。例如��,Nvidia的A100 GPU能夠提供高達(dá)312 TFLOPS的混合精度算力���。
2.2 數(shù)據(jù)傳輸效率
- 華為超節(jié)點(diǎn)芯片:通過(guò)優(yōu)化的片上網(wǎng)絡(luò)和內(nèi)存層次����,華為超節(jié)點(diǎn)芯片在數(shù)據(jù)傳輸效率上具有顯著優(yōu)勢(shì)。例如��,昇騰910芯片的片上網(wǎng)絡(luò)能夠?qū)崿F(xiàn)高達(dá)1.6 TB/s的帶寬��。
- Nvidia算力芯片:Nvidia的GPU依賴于高帶寬內(nèi)存技術(shù)���,數(shù)據(jù)傳輸效率較高����,但在復(fù)雜任務(wù)中可能存在通信瓶頸�。例如����,A100 GPU的HBM2內(nèi)存能夠提供1.6 TB/s的帶寬。
3. 應(yīng)用場(chǎng)景:從AI到高性能計(jì)算
3.1 華為超節(jié)點(diǎn)芯片的應(yīng)用場(chǎng)景
華為超節(jié)點(diǎn)芯片廣泛應(yīng)用于人工智能�����、高性能計(jì)算和邊緣計(jì)算等領(lǐng)域���。其多核異構(gòu)設(shè)計(jì)使其能夠靈活應(yīng)對(duì)多種計(jì)算任務(wù)����,例如:
- 人工智能:在深度學(xué)習(xí)訓(xùn)練和推理任務(wù)中,華為超節(jié)點(diǎn)芯片能夠提供高效的支持�����。例如��,在圖像識(shí)別任務(wù)中�����,昇騰910芯片的推理速度比傳統(tǒng)GPU快30%���。
- 高性能計(jì)算:在科學(xué)計(jì)算和工程仿真任務(wù)中�����,其高效的計(jì)算能力和數(shù)據(jù)傳輸效率能夠顯著提升性能����。
3.2 Nvidia算力芯片的應(yīng)用場(chǎng)景
Nvidia的算力芯片主要應(yīng)用于圖形處理��、深度學(xué)習(xí)和高性能計(jì)算。其CUDA架構(gòu)和Tensor Core技術(shù)使其在這些領(lǐng)域表現(xiàn)出色���,例如:
- 圖形處理:在游戲和專業(yè)圖形設(shè)計(jì)領(lǐng)域����,Nvidia的GPU是首選��。例如��,RTX 3080 GPU能夠提供高達(dá)36 TFLOPS的圖形處理能力�。
- 深度學(xué)習(xí):在大規(guī)模深度學(xué)習(xí)訓(xùn)練任務(wù)中,Nvidia的GPU能夠提供高效的計(jì)算支持�����。例如�,A100 GPU在訓(xùn)練BERT模型時(shí),比傳統(tǒng)CPU快100倍�。
4. 生態(tài)構(gòu)建:從硬件到軟件的全面布局
4.1 華為超節(jié)點(diǎn)芯片的生態(tài)構(gòu)建
華為通過(guò)開放的硬件平臺(tái)和完善的軟件生態(tài)系統(tǒng)��,推動(dòng)超節(jié)點(diǎn)芯片的廣泛應(yīng)用��。其生態(tài)構(gòu)建包括:
- 硬件平臺(tái):提供多種硬件配置����,滿足不同用戶的需求�����。
- 軟件生態(tài)系統(tǒng):通過(guò)開放的編程模型和豐富的開發(fā)工具�,降低開發(fā)門檻���。例如�,華為的CANN(Compute Architecture for Neural Networks)框架提供了高效的開發(fā)支持�。
4.2 Nvidia算力芯片的生態(tài)構(gòu)建
Nvidia的生態(tài)構(gòu)建以CUDA為核心,形成了一個(gè)龐大的開發(fā)者社區(qū)�����。其生態(tài)構(gòu)建包括:
- 硬件平臺(tái):提供多種GPU產(chǎn)品��,滿足不同應(yīng)用場(chǎng)景的需求��。
- 軟件生態(tài)系統(tǒng):通過(guò)CUDA編程模型和豐富的開發(fā)工具�,支持廣泛的開發(fā)需求。例如��,Nvidia的CUDA Toolkit提供了豐富的庫(kù)和工具�����。
5. 未來(lái)展望:技術(shù)發(fā)展趨勢(shì)與產(chǎn)業(yè)機(jī)遇
隨著技術(shù)的不斷進(jìn)步,華為超節(jié)點(diǎn)芯片和Nvidia算力芯片都面臨著新的發(fā)展機(jī)遇和挑戰(zhàn)�。未來(lái)的發(fā)展趨勢(shì)包括:
- 更高性能:隨著工藝技術(shù)的進(jìn)步,芯片性能將進(jìn)一步提升����。
- 更廣泛應(yīng)用:隨著人工智能和高性能計(jì)算的普及,芯片的應(yīng)用場(chǎng)景將更加廣泛�����。
- 更完善生態(tài):通過(guò)開放的硬件平臺(tái)和完善的軟件生態(tài)系統(tǒng)����,推動(dòng)技術(shù)的廣泛應(yīng)用。
結(jié)論
華為超節(jié)點(diǎn)芯片架構(gòu)和Nvidia算力芯片架構(gòu)是當(dāng)前芯片領(lǐng)域的兩大重要技術(shù)方向��。通過(guò)深入剖析其架構(gòu)設(shè)計(jì)����、性能表現(xiàn)、應(yīng)用場(chǎng)景和生態(tài)構(gòu)建��,我們可以看到兩者在技術(shù)理念和應(yīng)用領(lǐng)域上的差異����。華為超節(jié)點(diǎn)芯片以其多核異構(gòu)設(shè)計(jì)和高效的片上網(wǎng)絡(luò),在某些特定應(yīng)用場(chǎng)景中表現(xiàn)出色����;而Nvidia的算力芯片則以其強(qiáng)大的并行計(jì)算能力和廣泛的應(yīng)用生態(tài),成為業(yè)界的主流選擇�����。未來(lái)��,隨著技術(shù)的不斷進(jìn)步和應(yīng)用場(chǎng)景的不斷拓展��,兩者都將在芯片領(lǐng)域發(fā)揮重要作用����。
參考文獻(xiàn)
[Nvidia CUDA架構(gòu)技術(shù)白皮書]
[Nvidia Tensor Core Technical 白皮書]
[華為昇騰910芯片性能評(píng)測(cè)報(bào)告]
[華為昇騰910芯片技術(shù)規(guī)格][華為昇騰910芯片數(shù)據(jù)傳輸效率評(píng)測(cè)]
[Nvidia A100 GPU性能評(píng)測(cè)報(bào)告]
[Nvidia A100 GPU技術(shù)規(guī)格]
[Nvidia A100 GPU內(nèi)存技術(shù)白皮書]