最近,韓國半導體工程師學會(ISE)發(fā)布了《2026 年半導體技術路線圖》���,其中談到了半導體工藝發(fā)展到0.2nm的預測����,引起了不少關注�。但如果只把它當作一份“制程更先進、指標更激進”的技術預測���,反而容易忽略它真正想傳達的信息����。
這份路線圖以2025年為起點����,展望至2040年,對未來約15年的器件與工藝、人工智能半導體���、光互連、無線互連�、傳感器技術、有線互連���、存算一體(PIM)����、封裝技術及量子計算技術等九大半導體技術發(fā)展趨勢進行了系統(tǒng)性預測���。這并不是一份“更小制程”的路線圖�,而是一份關于半導體競爭形態(tài)正在發(fā)生改變的行業(yè)判斷���。
如果說過去的路線圖是關于“尺寸”的軍備競賽����,那么這份路線圖則是關于“范式”的全面重構����。讓我們穿透0.2nm這個極具沖擊力的數(shù)字,沿著它給出的九條技術主線�,去解析這本長達15年的“未來生存手冊”���。
1、器件與工藝技術路線圖
半導體產(chǎn)業(yè)過去數(shù)十年的主線只有一條——持續(xù)微縮���。通過縮小器件尺寸����,芯片在功耗�、成本和性能上不斷獲得紅利。最終產(chǎn)品的競爭力����,往往體現(xiàn)在更高速度、更高密度����、更低功耗、更小體積����、更低材料成本,以及更強的系統(tǒng)功能上�。
綜合 IRDS 的 More Moore IFT(國際重點團隊)研究成果,以及 IMEC 在 ITF World 2023 與 2024 上給出的前瞻預測,韓國的路線圖試圖回答一個核心問題:在大數(shù)據(jù)���、智能移動�、云計算與 AI 工作負載持續(xù)攀升的背景下���,邏輯與存儲技術如何在 PPAC(功耗–性能–面積–成本) 約束下繼續(xù)演進?
以量產(chǎn)級技術為基準����,這一技術路線圖從2025年起每3年為一個節(jié)點,描繪了邏輯與存儲器件在未來15 年(至2040年)的可能演進路徑�,涵蓋物理結構、電氣特性與可靠性等關鍵維度���。
邏輯技術趨勢:從2nm到0.2nm
邏輯器件工藝演進的核心目標始終未變:在更小的工藝間距和更低的工作電壓下�,維持性能與功耗的有效縮放(Scaling)����。然而,隨著尺寸不斷縮小���,一個現(xiàn)實問題愈發(fā)突出——寄生效應正在吞噬微縮紅利����。金屬互連、電容耦合�、電阻上升,使得負載在整體性能與功耗中的占比持續(xù)提高����,甚至可能抵消晶體管本身的改進。
這也直接推動了設計范式的轉變����。
過去,行業(yè)主要依賴 DTCO(Design-Technology Co-Optimization���,設計-工藝協(xié)同優(yōu)化)���,通過電路設計來彌補工藝微縮帶來的性能損失;而如今���,優(yōu)化的邊界被進一步拉大�,演進為 STCO(System-Technology Co-Optimization���,系統(tǒng)-工藝協(xié)同優(yōu)化)——優(yōu)化對象不再局限于單一芯片����,而是擴展至 Chiplet、先進封裝���、存儲層級�、互連結構����,乃至整個系統(tǒng)架構。
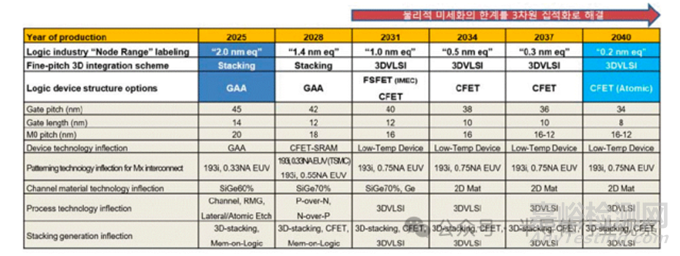
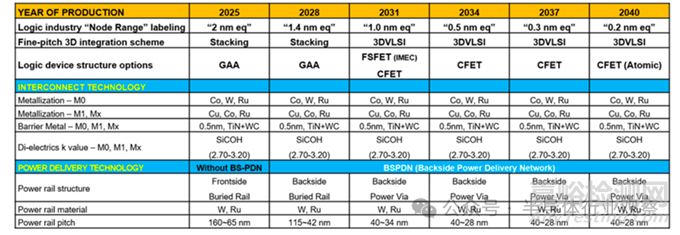
根據(jù)器件結構與關鍵工藝變量的路線圖預測�,邏輯器件的“名義節(jié)點”將從2025年的 2nm 級���,推進至2031年的1nm 級���,并在2040年前后逼近0.2nm量級。微縮的關鍵變量主要集中在四個方面:三維柵極結構與間距����、金屬布線Pitch、柵極長度(Lg)���、三維層疊與順序集成能力���。
邏輯器件的器件結構及工藝技術核心變量
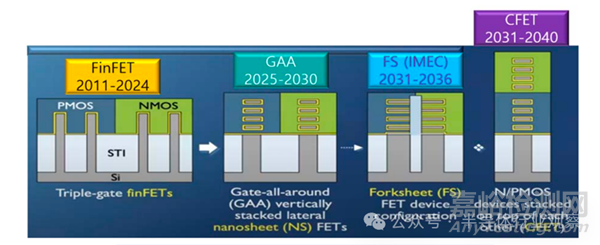
下圖顯示了器件結構的演進趨勢���。自 2025 年起,邏輯晶體管的主流結構將逐步從 FinFET 轉向 GAA(Gate-All-Around)���,F(xiàn)inFET 及 GAA 架構利用完全耗盡通道和完全反轉通道(體反轉)���。進一步地,F(xiàn)S-FET(Fork-Sheet FET) 通過在納米片之間加入絕緣層來分離 N 器件和 P 器件�,可大幅縮小器件尺寸。雖然在2031年左右引入 0.75NA EUV 可使線寬比現(xiàn)有的 0.33NA EUV 縮小 2.3 倍����,但物理微縮預計將趨于飽和。預計將通過 PMOS 和 NMOS 的三維集成����,即稱為 CFET(互補場效應晶體管)的 3D VLSI 方向來提升器件性能。預計 CFET(Complementary FET) 將進化為 P 器件堆疊在 N 器件之上的 3D 形式�。
晶體管結構的演進(來源:ITF World 2023 ,IMEC)
但CFET也引入了新的技術門檻���,低溫工藝成為剛需���,以避免上層器件制造對下層結構造成熱損傷�。在移動終端和邊緣計算快速普及的背景下���,降低工作電壓(Vdd) 已成為不可逆趨勢�。為了在低電壓條件下維持性能���,近年來邏輯器件研發(fā)的重點集中在幾項關鍵技術上:通道晶格應變(促進遷移率)���、HKMG(高k金屬柵極)、降低接觸電阻及改善靜電特性���。
進一步的微縮,正在從“器件層面”走向“結構層面”����。單片 3D(Monolithic 3D, M3D) 集成,使晶體管得以在同一晶圓上進行垂直堆疊����。短期目標仍然是單線程性能提升與功耗降低;而中長期���,則將演進為低 Vdd���、高并行度�、單位體積集成功能最大化的三維架構���。
與此同時���,3D 混合存儲器-邏輯(3D Hybrid Memory-on-Logic)方案,正在成為 AI 與 HPC 的關鍵突破口���。通過 Hybrid Bonding 直接連接邏輯與存儲芯片����,可顯著縮短數(shù)據(jù)路徑����、降低延遲,并提升系統(tǒng)能效���,這對 HBM���、AI 加速器����、端側 AI 尤為關鍵���。當然���,挑戰(zhàn)同樣明顯:異質芯片鍵合的良率與可靠性、高功耗器件(如 GPU + HBM)的散熱路徑設計����。
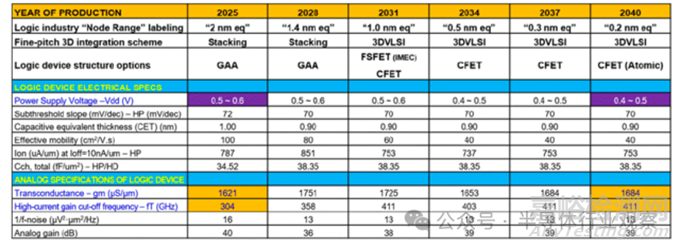
在 2025 年至 2040 年路線圖預測的 6 個技術節(jié)點中,隨著 2nm 級以下邏輯器件微縮的推進����,寄生元件導致的負載占比增加,受性能和功耗方面的負面影響�,工作電壓(0.5V~0.4V)不會有大幅改善,但跨導(Transconductance)等模擬特性將得以維持���。
邏輯器件技術路線圖
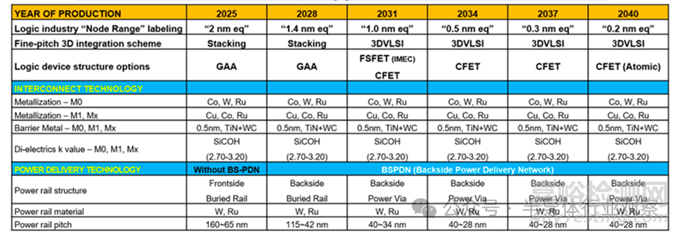
在 2nm之后,金屬布線成為限制性能的“第二戰(zhàn)場”�。行業(yè)需要同時滿足三項幾乎相互矛盾的目標:更低電阻、更低介電常數(shù)���、更高可靠性�。這對材料體系、刻蝕工藝和大馬士革(Damascene)集成精度提出了極高要求���。高深寬比結構下的RC退化���,使得先進計量、原位監(jiān)測與實時工藝控制成為不可或缺的基礎能力�。
在供電架構上,一個重要的變革正在發(fā)生——背面供電(Backside Power Delivery)����。通過將電源網(wǎng)絡從芯片正面移至背面,可以實現(xiàn):信號與電源路徑解耦/降低 IR Drop 與噪聲干擾/提升面積利用率與能效���。按照金屬布線微縮路線圖�,背面供電網(wǎng)絡(BSPDN) 預計將在 2028 年左右開始導入�,并在 2031 年后結合 Power Via 技術,將電源軌間距快速推進至 40nm 級別���。
金屬布線微縮路線圖
存儲技術趨勢與路線圖
如果說過去十年����,半導體產(chǎn)業(yè)的主角是計算,那么進入 AI 時代后���,真正的瓶頸正在快速轉移到存儲�。大模型訓練����、推理、檢索增強(RAG)以及多模態(tài)計算����,對數(shù)據(jù)吞吐、訪問延遲和能效提出了前所未有的要求����。數(shù)據(jù)中心與 AI 服務器所需要的,不只是“更大的容量”�,而是同時具備:高容量 × 高帶寬 × 低延遲 × 低功耗,正是在這一背景下�,存儲器從“配角”轉變?yōu)闆Q定系統(tǒng)上限的關鍵角色。
由于DRAM與非易失性存儲器(NVM)長期以標準化���、獨立產(chǎn)品形態(tài)引領存儲產(chǎn)業(yè)演進�,ISE的研究重點也主要圍繞這兩大技術體系展開���。嵌入式存儲(Embedded Memory)雖然路徑相似�,但在節(jié)點節(jié)奏上通常存在一定滯后�。
1、DRAM
DRAM 誕生至今已超過 40 年�,卻依然是計算系統(tǒng)中不可替代的工作內存。從 PC 的 DDR����、移動終端的 LPDDR,到 GPU 的 GDDR����、AI 加速器的 HBM,再到高速緩存用的 eDRAM����,DRAM 覆蓋了幾乎所有性能層級。
但問題在于:傳統(tǒng) DRAM單元結構���,已經(jīng)難以繼續(xù)按原路徑微縮����。
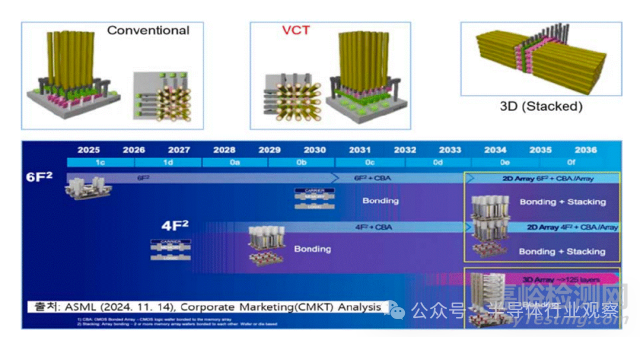
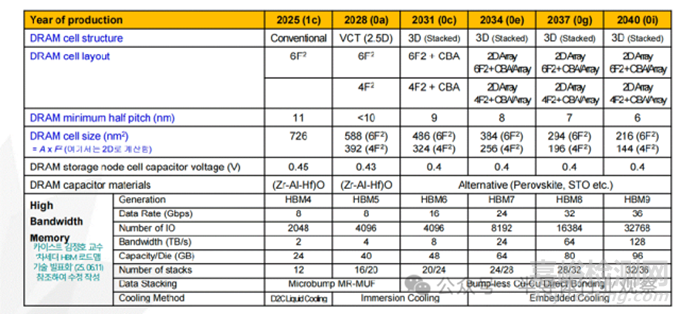
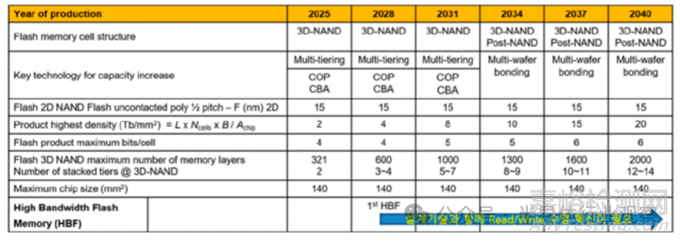
根據(jù)技術路線圖預測,DRAM 單元結構正在發(fā)生根本性變化(如下圖):單元晶體管將從傳統(tǒng)結構���,演進為垂直通道晶體管(VCT)����;存儲陣列將逐步引入堆疊型 DRAM(Stacked DRAM)�;單元面積從 6F² 向 4F² 極限逼近。更具顛覆意義的是����,CBA(CMOS Bonded to Array)技術開始浮出水面——通過混合鍵合,將 CMOS 外圍電路直接與存儲陣列集成����,有望突破傳統(tǒng)“陣列—外圍”分離架構的效率瓶頸。
在DRAM的技術演進過程中�,雙功函數(shù)字線、單側電容器工藝以及埋入式通道 S/A 晶體管已應用于 DRAM 產(chǎn)品中���,EUV光刻技術也已開始正式投入應用�。為了降低字線和位線的電阻并改善工藝����,目前正在研發(fā)包括釕(Ru)���、鉬(Mo)在內的多種新型材料。然而���,盡管付出了這些努力,預計基于BCAT(埋入式通道陣列晶體管)的DRAM 單元���,微縮極限大約停留在7–8nm�。
DRAM技術路線圖
為了突破平面 DRAM 的物理天花板�,行業(yè)正在同步推進多條探索路徑:High-NA EUV 的引入、X-DRAM 等 3D DRAM 架構����、4F² 單元與無電荷存儲 DRAM(Capacitorless DRAM)、電路級與運行機制優(yōu)化(如更精細的時鐘控制)�。與此同時,DRAM 工藝的“長期作業(yè)清單”也在不斷拉長:單元持續(xù)微縮���、外圍電路引入 HKMG����、字線/位線新材料(Ru�、Mo 等)����、更高質量的高 k 電容介質����、面向 3D DRAM 的工藝穩(wěn)定性控制。從中長期看����,高容量混合鍵合 DRAM 芯片,以及高層數(shù) HBM 的晶圓級封裝能力���,正逐步成為競爭分水嶺�。
隨著 AI訓練規(guī)模指數(shù)級放大���,HBM(高帶寬存儲器)成為增長最快的存儲細分市場����。它通過多顆 DRAM Die 的垂直堆疊�,實現(xiàn)了高帶寬、低功耗�、近計算的數(shù)據(jù)供給模式。HBM預計將從2025 年 12 層�、2TB/s 帶寬����,發(fā)展至2031年20 層����、8TB/s 帶寬,并在2040年達到30層以上����、128TB/s的帶寬水平(上圖)���。HBM 的核心技術挑戰(zhàn)集中在:TSV 工藝與良率���、均勻供電與功耗管理、熱路徑與散熱�、微凸點 / 混合鍵合接口、I/O 數(shù)量持續(xù)擴展����。進一步看,HBM 的意義已經(jīng)超出“存儲器件”本身�。要真正突破馮·諾依曼瓶頸,PIM(存內處理)����、CIM(存內計算)���、AIM(加速器內存)等新范式,正圍繞 HBM與GDDR架構同步推進����。同時,CXL存儲器也被視為數(shù)據(jù)中心級別不可或缺的關鍵拼圖����。
2、NVM:Flash還在長高����,但路越來越窄
非易失性存儲器的應用跨度極大,從 Kb 級嵌入式系統(tǒng)到 Tb 級數(shù)據(jù)中心�,其技術路徑也高度分化。
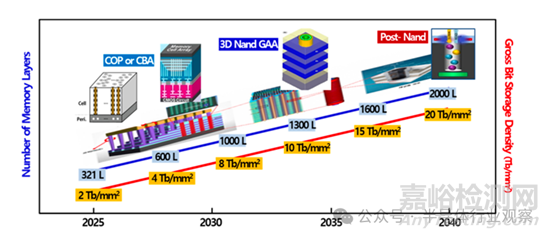
Flash存儲基于 1T 單元���,在二維平面下幾乎無法繼續(xù)提升密度����。真正讓NAND走到今天的�,是3D堆疊���。當前3D NAND 的核心難題,并不在電學原理����,而在制造本身:超高深寬比深孔刻蝕、多層介質與多晶硅沉積�、晶圓翹曲(Warpage)控制、高精度計量與缺陷監(jiān)測�。3D-NAND 技術方面,產(chǎn)業(yè)界已經(jīng)給出清晰節(jié)奏:321 層閃存已于 2025 年開始量產(chǎn)���;預計 2028 年后可實現(xiàn) 600 層,2031 年左右實現(xiàn) 1000 層�。若能應用工藝微縮及 3D 混合鍵合技術,預計到 2040 年甚至有望達到 2000 層���。但層數(shù)越高�,字線接觸結構的面積開銷也隨之放大���。因此����,Word Line Pitch 必須快速壓縮,近期已逼近 40nm 以下�。
在單元層面,QLC 已全面商用�,PLC 也在推進之中。但每增加一bit����,意味著:編程/讀取時間更長、電平間隔更窄�、可靠性壓力更大,這是一場典型的性能—成本—可靠性三方博弈�。
3、下一代非易失性存儲
除了 Flash���,業(yè)界也在持續(xù)探索不依賴電荷存儲的新型 NVM�,包括 FeRAM���、MRAM����、PCM���、ReRAM 等����。但要取代現(xiàn)有器件,在技術上仍存在大量有待解決的問題���。
FeRAM / FeFET:依托 HfO? 鐵電材料�,有望實現(xiàn)低功耗����、極速的類 Flash 1T 存儲,尤其適合嵌入式場景���。
STT-MRAM:難以在短期內取代大容量 NAND����,但在嵌入式 NOR 替代上潛力明確����。
NOR Flash:由于成熟�、穩(wěn)定、耐高溫焊接���,仍將在嵌入式系統(tǒng)中長期存在����。
3D Cross Point / SCM:通過 BEOL 工藝實現(xiàn)多層堆疊,在吞吐量���、能效和成本之間取得平衡����。
在這些方案中����,PCM 被認為是縮放潛力最均衡的路線,而 ReRAM 則仍需克服一致性與波動性問題�。
2、人工智能半導體路線圖
AI/ML 的快速發(fā)展�,直接催生了一個規(guī)模龐大的專用計算硬件市場。預計到 2025 年���,AI 相關計算將占全球計算需求的約 20%�,對應數(shù)百億美元級別的市場規(guī)模�。從硬件角度看,當前主流 AI/ML 平臺主要包括以下幾類:CPU�、GPU、ASIC、數(shù)字 ASIC 加速器���、CIM(存內計算)�、模擬 ASIC 加速器���。
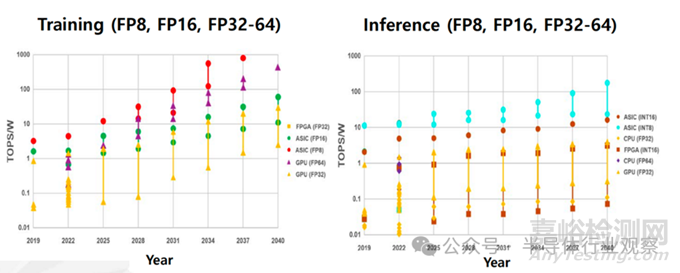
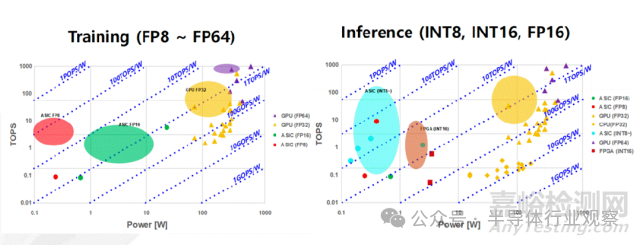
人工智能半導體技術可分為訓練和推理兩類����,其性能表現(xiàn)會隨著所采用的硬件和計算精度而呈現(xiàn)出較大的差異����。用于訓練的計算能力預計將從 2025 年的 0.1~10 TOPS/W,發(fā)展到 2040 年的 5~1000 TOPS/W���;用于推理的計算能力預計將從 2025 年的 0.1~10 TOPS/W���,提升至 2040 年的 1~100 TOPS/W。然而����,這一趨勢是基于當前計算精度假設得出的����,在未來若出現(xiàn)新的精度形式�,預測數(shù)值可能會發(fā)生變化����。總體而言���,所需且可實現(xiàn)的計算能力預計將根據(jù)具體應用進行優(yōu)化并呈現(xiàn)出不同的水平����。
訓練和推理用硬件的計算效率發(fā)展趨勢
訓練和推理用硬件的性能與系統(tǒng)功耗
在超連接技術體系中,數(shù)據(jù)的生成����、傳輸與處理能力正逐漸成為決定系統(tǒng)上限的關鍵因素。隨著人工智能(AI)與高性能計算(HPC)規(guī)模持續(xù)擴張���,傳統(tǒng)依賴銅互連的電連接方式����,正日益暴露出在帶寬、功耗�、延遲與系統(tǒng)復雜度方面的瓶頸。
在這一背景下����,光連接(Optical Interconnect) 被視為突破互連瓶頸的核心技術路徑之一。它不僅已廣泛應用于現(xiàn)有數(shù)據(jù)中心內部與數(shù)據(jù)中心之間的高速通信���,還在 AI 與 HPC 驅動的云計算系統(tǒng)中���,承擔著超高速大規(guī)模數(shù)據(jù)流動的基礎設施角色,并逐步向數(shù)據(jù)生成���、協(xié)同計算與實時分析等環(huán)節(jié)延伸�。
從更長遠的視角看����,光連接的應用邊界正在持續(xù)擴展:面向物聯(lián)網(wǎng)(IoT)的光傳感與邊緣連接,光纖到戶(FTTH)�,汽車、航空航天����、醫(yī)療與工業(yè)自動化�,自由空間光互連(FSOI)�、LiFi 等新型通信方式以及與量子計算系統(tǒng)的深度融合�。同時����,結合先進半導體器件與封裝工藝�,將光器件與電子器件在更緊密的尺度上集成�,也被認為是光連接技術實現(xiàn)跨代躍遷的重要方向����。
當前,光連接最直接的價值在于克服銅互連的物理極限����。在高頻高速條件下�,銅互連不可避免地面臨信號衰減���、串擾、功耗上升����、散熱困難以及系統(tǒng)運營成本上升等問題����。相比之下���,光連接在帶寬密度����、傳輸距離和能效方面具有天然優(yōu)勢����。
最初,光連接主要應用于局域網(wǎng)、無線通信基站�、數(shù)據(jù)中心之間的長距離通信(>40 km)���,以及數(shù)據(jù)中心內部系統(tǒng)之間的互連����。近年來,隨著 AI 與 HPC 對數(shù)據(jù)吞吐需求呈指數(shù)級增長���,光連接開始向計算單元內部以及計算單元之間延伸,成為支撐算力擴展的關鍵基礎設施����。
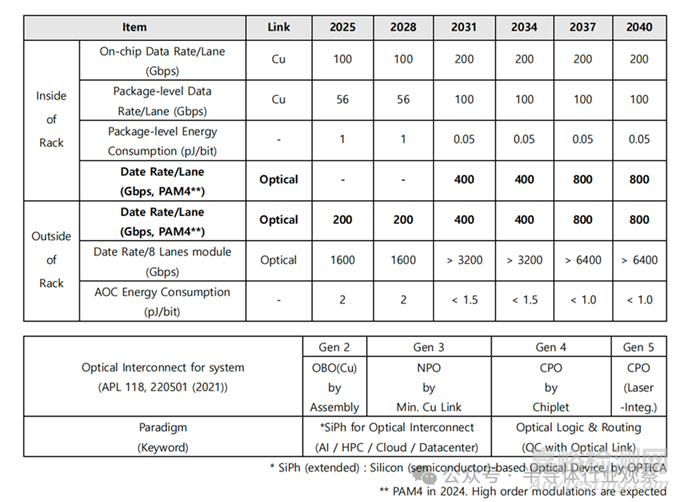
在光連接半導體技術路線圖中�,數(shù)據(jù)中心被視為最核心的應用起點。圍繞這一場景����,光連接技術通常從兩個維度進行劃分:按系統(tǒng)結構可分為系統(tǒng)內部光連接(Inside-of-Rack)���、系統(tǒng)間光連接(Outside-of-Rack);按傳輸距離可細分為XSR(<1 m)���、SR(<100 m)����、DR(<500 m)����、FR(<2 km)。不同距離與系統(tǒng)形態(tài)�,對材料�、器件、封裝與系統(tǒng)架構提出了截然不同的要求。
無論具體實現(xiàn)形式如何�,光連接的本質都是通過電–光與光–電轉換實現(xiàn)高速數(shù)據(jù)傳輸。圍繞這一核心����,當前的技術演進主線可以概括為 CPO(Co-Packaged Optics)。在實際產(chǎn)品中����,通常根據(jù)系統(tǒng)邊界將其區(qū)分為兩類:
Inside-of-Rack CPO:用于系統(tǒng)內部�,替代 PCB 上的銅互連
Outside-of-Rack 可插拔式收發(fā)器/交換機:用于系統(tǒng)之間連接
第一代:銅互連為主���,光作為補充
在早期架構中���,計算器件間的數(shù)據(jù)主要通過 PCB 上的銅互連傳輸。隨著速率提升���,信號失真、串擾與延遲問題愈發(fā)嚴重�,需要引入 Retimer 或 DSP 才能勉強維持性能�,導致系統(tǒng)功耗���、成本與復雜度顯著上升�。
第二代:OBO 緩解問題,但仍未根治
通過縮短銅互連長度、引入 OBO(On-Board Optics)����,可在一定程度上降低損耗與功耗�。但在 >100 Gbps/lane 的速率需求下����,銅互連的物理限制仍然存在����。
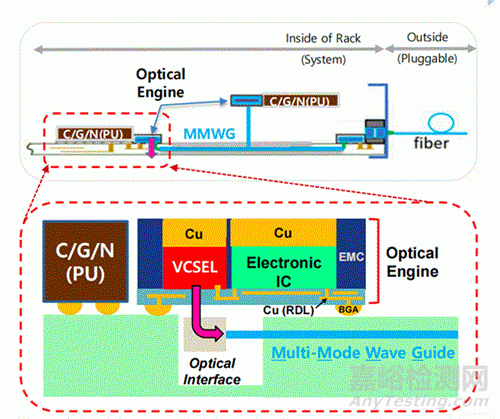
第三代:NPO�,光靠近計算
NPO(Near-Packaged Optics) 通過將光引擎以可插拔或半固定方式布置在靠近計算器件的位置�,用光互連取代 PCB 上的高速銅線�。目前�,基于 VCSEL 的多模方案正在通過國際聯(lián)合研究持續(xù)推進���。
第四代:真正的 CPO
在 CPO(Co-Packaged Optics) 架構中,計算芯片與光引擎在封裝層面集成為單一芯粒(Chiplet),外部銅互連被徹底消除����。晶圓級封裝與裝配技術,被視為推動這一代技術落地的關鍵。
第五代:無 PCB 的光系統(tǒng)
從更長遠看,光連接將引入外置或集成激光系統(tǒng)(ELS / ILS),并結合單片光電集成技術����,逐步演進為無需 PCB 的光互連系統(tǒng)����。
要在系統(tǒng)層面實現(xiàn)高速�、低功耗光連接,必須依賴光集成電路(PIC)����。其核心在于將激光���、調制����、復用����、探測等功能���,在半導體工藝與封裝層面實現(xiàn)高密度集成�。當前,基于 SOI 的硅光子技術已較為成熟����,但在調制器尺寸�、功耗與溫度穩(wěn)定性方面仍存在挑戰(zhàn)�。TFLN����、III-V/Si 異質集成�、等離激元與非周期納米光子結構,正被視為突破現(xiàn)有瓶頸的關鍵方向。從調制器、MUX/DEMUX、波導,到最終的光交換與光路由,光連接技術正逐步從“通信器件”�,演進為具備計算與邏輯能力的系統(tǒng)級基礎設施����。
綜合光連接路線圖與當前光連接產(chǎn)業(yè)的現(xiàn)狀����,預測到 2040 年的中長期技術開發(fā)路線圖如下所示���,并以單通道(Lane�,1 根光纖)可實現(xiàn)的數(shù)據(jù)傳輸速率為基準進行整理。在中期階段���,光連接將從 2025 年起逐步導入基于 PAM4 的 200Gbps/lane 方案,并向 400Gbps/lane 演進����;與此同時���,系統(tǒng)內部光連接將進入第三代NPO(Near-Packaged Optics) 的探索與導入階段���。更關鍵的是���,這一階段預計將推動形成硅光子相關的產(chǎn)業(yè)標準����,為后續(xù)更激進的封裝集成與系統(tǒng)架構演進打下統(tǒng)一接口與規(guī)?���;A����。
光連接半導體技術路線圖
從長期來看���,路線圖指向 800Gbps/lane 以上的單通道能力�,這將推動第四代CPO進入更廣泛的實際應用���。與此同時,為了支撐超高速傳輸并進一步降低能耗�,系統(tǒng)架構將逐步引入兩條關鍵路徑:盡量減少電/光轉換次數(shù)的混合電/光(Hybrid E/O)體系����;面向更極致目標的 光邏輯(Optical Logic) 與光學信息處理能力�。更進一步����,圍繞光邏輯的材料���、器件���、系統(tǒng)技術體系�,以及與量子計算的融合協(xié)同,有望在“超高速計算 + 超高速互連”這一組合領域帶來非線性級別的突破���。
為了支撐上述路線���,未來約 5 年的中期階段�,核心工程問題集中在“能跑得更快����、跑得更穩(wěn)、跑得更省”三件事上:
速率提升與信號完整性:在更高速率下抑制失真與誤碼
延遲下降:將信號等待時間從“數(shù)微秒”壓到“數(shù)納秒”量級
功耗與熱管理:降低驅動功耗與發(fā)熱,控制系統(tǒng)總功耗
小型化與高密度:在更小的 Form Factor 內實現(xiàn)更高帶寬密度
與此同時,光連接向其他產(chǎn)業(yè)擴展����,也將以“光引擎 + 類似原理的光傳感器”為技術支點,尤其是 ToF / LiDAR 形態(tài)的三維測距能力����,進入智能手機���、車載系統(tǒng)等規(guī)?���;脚_,并進一步推動航空航天����、醫(yī)療���、工業(yè)現(xiàn)場與家庭場景的輕薄短小新系統(tǒng)導入。
對于當前最主要的應用場景——數(shù)據(jù)中心大數(shù)據(jù)傳輸——光連接將在 AI/LLM 訓練推理、高性能計算(HPC)與多形態(tài)云系統(tǒng)中持續(xù)擴大滲透����,并在緩解數(shù)據(jù)瓶頸、降低能耗、減少設施運維成本與推動環(huán)保等方面給出系統(tǒng)級解法。
長期(約 15 年)真正難啃的骨頭�,是數(shù)據(jù)中心互連的結構性問題:即便大量引入光連接���,只要系統(tǒng)仍頻繁經(jīng)歷電/光/電的往返轉換�,延遲與功耗的上限就仍然存在。因此���,路線圖提出的關鍵對策之一�,是引入光學路由(Optical Routing)?���;?MEMS 的混合電/光路由(Hybrid E/O Routing)已經(jīng)在實驗層面展示了可行性,并有潛力從系統(tǒng)間互連擴展到系統(tǒng)內部:包括計算裝置之間�、計算與存儲之間的數(shù)據(jù)流動���。
要讓光學路由真正成為“體系能力”���,前提是引入某種形式的光學邏輯(Optical Logic),使系統(tǒng)能夠在光域完成:指令解碼���、可用路徑識別、數(shù)據(jù)流切換與沖突處理����。這可能意味著:不僅需要新材料、新器件與新結構�,還需要圍繞“盡量少做一次電/光/電轉換”建立統(tǒng)一的標準接口與適配體系���。
更激進也更具想象力的方向,是光學邏輯與量子計算的結合���。一旦這條路徑成熟���,它可能成為真正的“規(guī)則改變者”:在提升速率、降低失真����、壓縮等待時間�、降低功耗與實現(xiàn)高密度集成等維度同時帶來躍遷。
在更前沿的方向上���,路線圖還指向用于通信的結構光����。例如,將軌道角動量引入數(shù)據(jù)傳輸�,可實現(xiàn)模式分割復用,并與 WDM(波分復用)���、PDM(偏振復用)疊加�,從而在理論上打開更大的容量空間。此外���,一系列面向“光子信號可控性”的潛在關鍵技術——包括光學放大����、調制(波長/偏振/方向)、乃至激活光子存儲器——也可能成為下一代光連接系統(tǒng)的重要拼圖����。
4、無線連接半導體路線圖
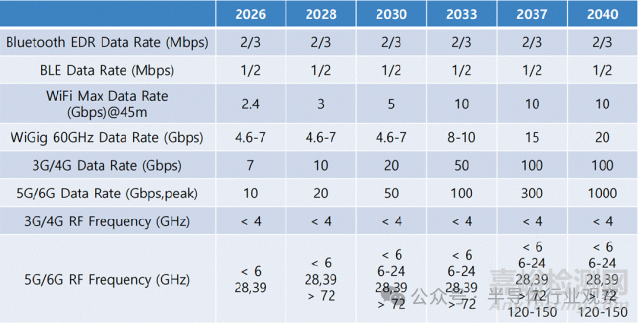
在無線連接領域���,下圖是ISE預測的無線連接技術路線圖:對于 3G/4G/5G 的 Sub-6GHz 主戰(zhàn)場����,峰值速率目前處于數(shù) Gbps 水平�,未來隨著基站/終端硬件能力與調制技術提升�,預計到 2040 年前后可達到數(shù)十至 100Gbps量級。對于 5G/6G 的高頻擴展路徑����,毫米波與亞太赫茲將被更積極地利用�。6G 世代的目標指向 0.1~1Tbps(100~1000Gbps)峰值速率,并預計在 2040 年左右���,Tbps 級鏈路將在部分應用場景中實現(xiàn)落地����。
無線連接技術路線圖發(fā)展趨勢
LPWAN、Bluetooth、Wi-Fi 與 5G/6G 等多種標準仍在競爭與分工中共存���,為 IoT 設備提供多層次連接能力。由于大量終端需要在極低功耗下長期運行�,無線通信器件與電路必須持續(xù)提升能效。與此同時����,面向 5G/6G 的有源相控陣天線已經(jīng)取得顯著進展:高指向性不僅能以更低功耗實現(xiàn)更遠距離通信���,還能降低干擾并提升鏈路安全性����。更現(xiàn)實的工程趨勢是:將不同材料體系(CMOS/SiGe BiCMOS 與 III-V 等)的器件能力����,通過 hybrid 電路設計與先進封裝集成為單一系統(tǒng)����,正在成為高性能無線平臺的關鍵路徑之一。
更重要的是���,未來 5G 演進與 6G 愿景的目標���,已不再是單純把峰值速率做高�,而是走向“綜合質量指標”的系統(tǒng)級提升:時延���、能效���、可靠性將與吞吐量同等重要����。6G 愿景中提出將端到端時延從毫秒級壓到 數(shù)百微秒以下����,并將每比特能耗降至 數(shù)十 pJ/bit以下——這意味著無線連接半導體必須在核心模塊上持續(xù)突破:更高效率且更高線性的 PA、更低相位噪聲的頻率合成器,以及支撐大規(guī)模相控陣與波束成形的 RF-SoC 平臺。
在 6G 時代,ISAC(感知與通信一體化)預計將成為無線連接半導體的重要應用方向:同一套 RF 前端與基帶平臺既要做通信,也要做高分辨率雷達感知�。除傳統(tǒng) PA/LNA 與頻率合成器外,還需要脈沖生成電路、高速高分辨率 ADC�,以及能夠對公共硬件資源進行動態(tài)重構的 RF-SoC 架構���。與此同時,隨著低軌衛(wèi)星(LEO)推動的 NTN(天地一體化網(wǎng)絡)擴展���,面向衛(wèi)星終端的 RF 前端與波束成形芯片組需求也將顯著增長���。在這一領域����,GaN HEMT���、InP HEMT 等 III-V 器件與 CMOS/SiGe BiCMOS的融合設計與封裝能力����,可能成為決定系統(tǒng)性能���、成本與可規(guī)?;潭鹊年P鍵���。
5���、傳感器技術
隨著人工智能在產(chǎn)業(yè)中的深入應用,減少人工干預�、提升系統(tǒng)自主性正在成為主流范式。作為自動化系統(tǒng)的核心輸入端�,傳感器在精度、可靠性與信息維度上持續(xù)演進����。受益于半導體工藝進步與新材料引入�,傳感器不僅測得更準����,也開始獲取過去難以檢測的新信息。按照信息獲取方式���,本路線圖將傳感器劃分為成像傳感器與檢測類傳感器���,并在此基礎上討論其技術演進方向及與 AI 的融合趨勢。
1�、圖像傳感器技術演進
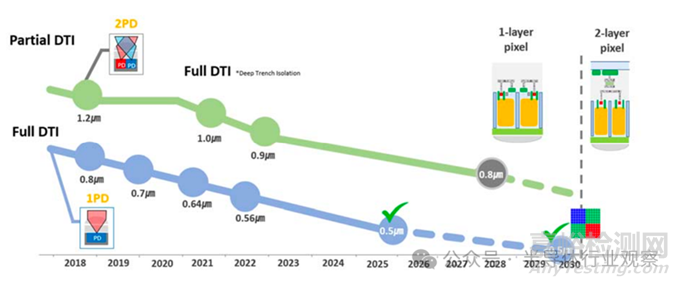
對于可見光圖像傳感器而言,像素微縮仍是核心主線����。過去二十年中,消費級 CIS 像素尺寸從 5.6 μm 縮小至 0.5 μm����,圖像質量卻持續(xù)提升�,關鍵在于多次結構性創(chuàng)新:PPD 降低噪聲與暗電流���、BSI 將填充因子提升至接近 100%、DTI / FDTI 抑制像素串擾����、Tetra Pixel 結合算法提升低照度性能�。
像素微縮趨勢與關鍵技術
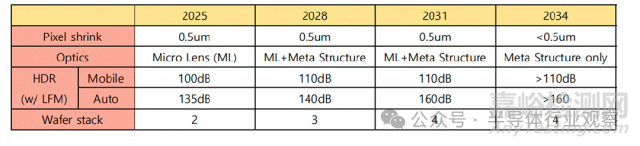
隨著像素進入亞微米尺度�,靈敏度、串擾與光衍射成為瓶頸����,未來像素微縮節(jié)奏將放緩���。為突破靈敏度限制�,超構光學(meta optics) 等新型光學結構開始受到關注。HDR 技術方面����,多重曝光與單次曝光并行發(fā)展。面向視頻與車載應用,行業(yè)正加速采用多種單次曝光方案,并將 LED Flicker Mitigation(LFM) 作為關鍵競爭指標���。車載 CIS 已實現(xiàn)單次曝光超過 120 dB 的動態(tài)范圍。在基礎性能上,隨機噪聲(RN) 隨工藝與電路優(yōu)化持續(xù)降低����,未來有望進入 1 e? 以下���;功耗在性能提升背景下仍受控,整體呈下降趨勢�。在結構上,晶圓堆疊(2-stack → 3-stack) 正成為高性能 CIS 的標配���,并為新型傳感器結構釋放空間����。
下一代成像結構的發(fā)展趨勢如下:
全局快門(GS)/混合 GS:通過 3D 堆疊等技術緩解 GS 在噪聲與像素尺寸上的劣勢���,推動其向移動端滲透����。
數(shù)字像素傳感器(DPS):像素內集成 ADC����,天然支持 GS 與高幀率,借助 3D 堆疊逐步向消費級應用靠近�。
光子計數(shù)傳感器(PCS):具備單光子檢測能力,在極低照度下優(yōu)勢顯著,但在像素尺寸�、功耗與成本上仍面臨挑戰(zhàn),短期內主要處于研究與探索階段�。
可見光傳感器技術路線圖
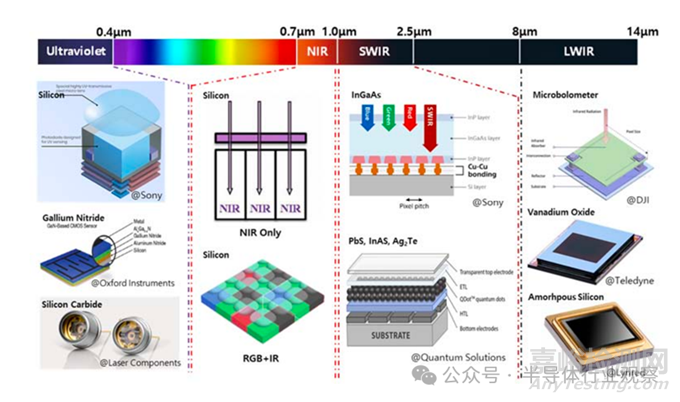
2、非可見光圖像傳感器
非可見光傳感器覆蓋 UV���、NIR、SWIR���、LWIR 波段���,應用從軍用擴展至工業(yè)、醫(yī)療�、自動駕駛等領域。
非可見光波段圖像傳感器的吸收材料
UV(200–400 nm):以硅基為主�,但受限于表面吸收過強與 QE 偏低,正探索 PQD�、SiC、GaN 等寬禁帶材料����。
NIR(700–1000 nm):仍沿硅基路線演進,SPAD 技術推動 LiDAR 與低照度應用發(fā)展����;RGB+IR 結構成為新趨勢���。
SWIR(1.0–2.5 μm):當前以 InGaAs 為主,性能優(yōu)但成本高����;QD(PbS、InAs�、Ag?Te) 與 Ge 被視為潛在替代方案,關鍵在于 QE���、RoHS 合規(guī)與量產(chǎn)能力���。
LWIR(8–14 μm):以微測輻射熱計(VOx / a-Si)為主,受限于工藝復雜與像素微縮難度���,材料與結構簡化仍是研究重點����。
3����、事件驅動與檢測類傳感器
事件驅動視覺傳感器(EVS) 以異步方式僅輸出光強變化事件���,具備高時間分辨率與低功耗優(yōu)勢,適合高速目標檢測����。未來發(fā)展重點包括:像素微縮、低照度與 HDR 改善�,以及 事件信號處理 IP 與 On-sensor AI 的引入。
4����、面向 AI 時代的傳感器趨勢
三條方向尤為明確:
In-Sensor DNN:在 CIS 內部集成 DNN����,僅輸出特征或元數(shù)據(jù),可獲得 百倍級能效優(yōu)勢����,緩解接口與帶寬瓶頸。
超低功耗(AON):通過情境感知�、ROI 讀取與輕量模型,實現(xiàn)“常開但不耗電”的感知體系����。
多傳感器融合:融合視覺����、雷達���、LiDAR����、IMU 等信息����,提升系統(tǒng)魯棒性,并向協(xié)同感知(V2X / CP)演進�。
總的來說,傳感器正從“記錄世界”走向“理解世界”�。在單一性能指標逐步逼近極限的背景下,AI 驅動的計算前移����、結構創(chuàng)新與多傳感器融合將成為決定未來傳感器價值的關鍵因素。傳感器不再只是數(shù)據(jù)源����,而是 智能系統(tǒng)中的主動計算節(jié)點。
傳感器技術發(fā)展動向路線圖
6���、有線互連半導體技術
有線互連可定義為:在半導體系統(tǒng)中利用金屬布線實現(xiàn)芯片間通信的技術���。按集成層級可歸納為三條主線:
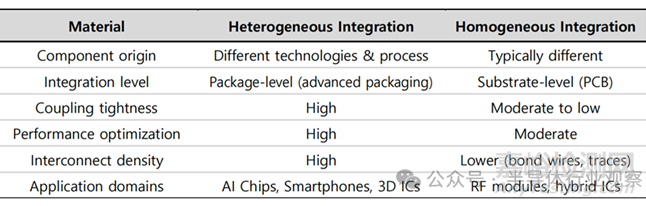
1�、封裝層級:異構集成
異構集成在封裝層實現(xiàn)系統(tǒng)級集成����,典型形式包括中介層(interposer)與芯粒(chiplet)架構。中介層的核心價值在于用具備更高布線密度的結構/材料����,替代傳統(tǒng)封裝基板,以縮短互連距離并提升 I/O 密度����,從而改善信號傳輸能力����。
上圖對比了異構集成與單片集成的差異,如上所述�,異構集成中最具代表性的核心推動要素是中介層
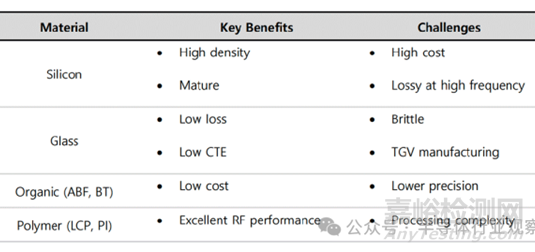
上圖進一步比較不同材料中介層的優(yōu)勢與局限。由于材料特性差異明確����,中介層選擇應由系統(tǒng)目標(損耗����、成本����、集成度、可靠性等)驅動
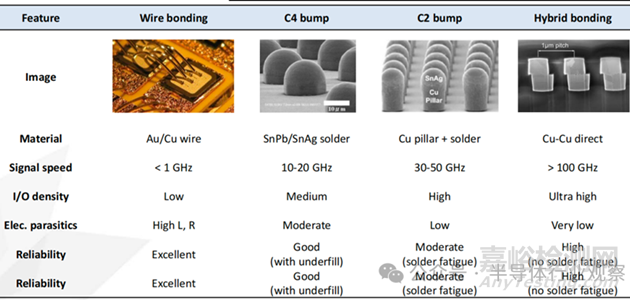
封裝中主要互連方式比較
用于高速系統(tǒng)封裝中有線互連的互連技術主要可分為四類����,按開發(fā)順序依次為:(1)引線鍵合(wire bonding,WB)�,(2)受控塌陷芯片連接(controlled collapse chip connection,C4)凸點�,(3)芯片連接(chip connection,C2)凸點����,以及(4)混合鍵合(hybrid bonding)。如上表中所示����,引線鍵合雖然具有較高的可靠性,但由于其電氣寄生參數(shù)較大����,可傳輸?shù)男盘枎捦ǔ5陀?1 GHz�。C4 凸點采用錫-鉛合金����,相較于 WB 具有更短的互連長度和更小的寄生參數(shù),其可支持的信號帶寬一般在 10–20 GHz 范圍內���。為進一步提升 C4 凸點的集成密度���,引入了銅柱(Cu pillar),并在此基礎上提出了 C2 凸點技術���,以實現(xiàn)更高的互連密度�。最后����,通過同時實現(xiàn)介電材料與銅的鍵合,提出了混合鍵合技術���,從而達成目前最高集成度的互連方案。
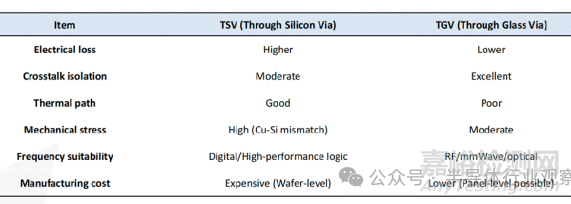
在中介層中����,關鍵的連接要素是硅通孔(Through Silicon Via���,TSV),其長度相比傳統(tǒng)互連方式如引線鍵合(WB)要短得多����。互連長度的縮短可顯著降低寄生電感與電阻�,從而改善信號傳輸特性。借助 TSV�,不僅可以提升半導體系統(tǒng)的集成度,還能夠同步提高系統(tǒng)性能���。在硅中介層中使用的 TSV�,在玻璃基板中對應的是玻璃通孔(Through Glass Via����,TGV)。與 TSV 類似�,TGV 也是一種垂直互連結構。下表對 TSV 與 TGV 進行了比較���,其主要差異來源于材料特性的不同���。這種差異主要是由于硅與玻璃的介電常數(shù)不同所致����,介電常數(shù)反映了材料對高頻信號的響應特性���。正因如此�,硅和玻璃在實際應用中的使用領域各有側重����;此外,玻璃基板還可實現(xiàn)面板級工藝����,在成本方面也具備一定優(yōu)勢。
TSV與TGV的比較
2����、芯片層級:芯粒(Chiplet)
芯粒將原本單片制造的整體芯片拆分為多個子芯片單元,分別采用更合適的工藝制造����,并在封裝階段集成??梢岳斫鉃椋褐薪閷悠?ldquo;封裝層提升集成”����,芯粒偏“硅層拆分重組提升集成”�。
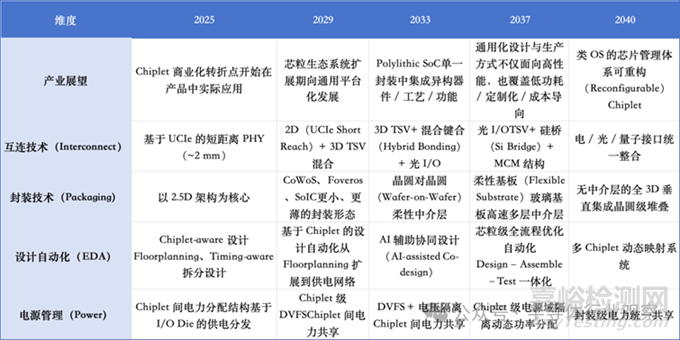
Chiplet技術路線圖
產(chǎn)業(yè)趨勢:芯粒將經(jīng)歷商業(yè)化落地與生態(tài)擴展階段�,系統(tǒng)架構向集成多類異構芯片的 Polylithic SoC 演進,并圍繞標準接口形成通用設計與制造體系�;長期看,資源與功能的統(tǒng)一管理有望上升到 OS/系統(tǒng)層的“芯片管理”范式�。
芯粒互連標準:主要包括 BoW����、AIB、UCIe���。其中 UCIe 采用差分串行鏈路���,支持均衡與編碼,并引入 CDR(時鐘數(shù)據(jù)恢復)���,減少對獨立時鐘分發(fā)的依賴����。綜合信號完整性、抗噪與可擴展性�,UCIe 在有限帶寬條件下優(yōu)勢更突出,且可支持更長互連距離(最高可達 10 mm)���,因此更適合高性能芯粒架構����。
封裝技術:早期以 2.5D(如 CoWoS�、Foveros、SoIC 等)提升互連密度并保證 SI����;隨后 Wafer-on-Wafer 與柔性基板提升堆疊自由度;長期目標是減少中介層依賴�、走向更徹底的 3D 垂直集成。
設計自動化:從 chiplet-aware 設計到 AI 輔助協(xié)同優(yōu)化�,最終走向可對多芯粒進行動態(tài)映射與全系統(tǒng)級優(yōu)化的高度自動化體系。
電源管理:從芯粒間供電路徑優(yōu)化���,到芯粒級 DVFS���,再到封裝層面電力共享與協(xié)調的統(tǒng)一管理。
3����、電路層級:SerDes 演進
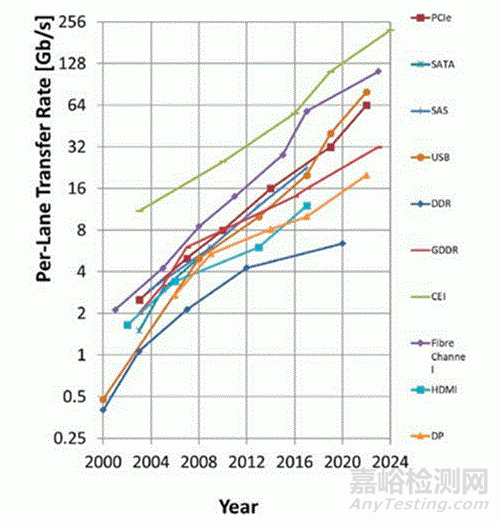
SerDes 是高速互連的關鍵:將大量數(shù)字信號映射為高速鏈路可承載的信號形式�,實現(xiàn)可靠傳輸����。下圖展示了 2000–2024 年不同 SerDes 標準規(guī)定的數(shù)據(jù)速率演進趨勢:速率提升不僅持續(xù)推進�,而且呈現(xiàn)近似指數(shù)增長。這意味著有線互連所需的頻率帶寬同樣以指數(shù)方式增加�。
SerDes 規(guī)格中數(shù)據(jù)傳輸速率的發(fā)展趨勢
下表對代表性標準(PCIe、以太網(wǎng)�、USB 等)進行對比:速率整體仍延續(xù)指數(shù)提升。為在帶寬受限的條件下提高有效傳輸能力���,業(yè)界正持續(xù)采用更高頻譜效率的 PAM 多電平傳輸�;時鐘逐步走向嵌入式/恢復式方案以減少布線并緩解相位不匹配�;均衡成為標配,其中 CTLE 幾乎普遍采用�,DFE/FFE 按通道需求選擇性引入。
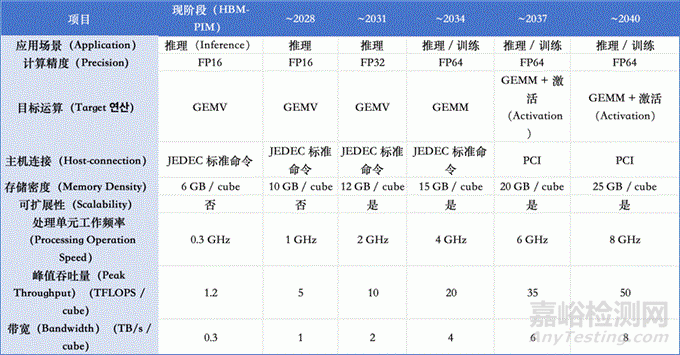
7�、PIM(存內計算,Processing-In-Memory)技術
PIM技術可視為對傳統(tǒng)馮·諾依曼架構在AI時代的一次體系級回應���。PIM 的核心思想是在存儲層附近或內部執(zhí)行計算�,以最小化“算—存”之間的數(shù)據(jù)傳輸。根據(jù)計算單元與存儲單元的物理位置關系���,PIM 技術可分為三類:PIM 技術可以具體分為 CIM����、PIM 和 PNM 三類���。按照這一分類����,CIM 更偏向于計算能力�,而 PIM 更偏向于存儲能力。借助 TSV 等新一代芯片互連技術�,PNM 架構有望同時最大化 CIM 與 PIM 各自的優(yōu)勢。ISE的路線圖正是將這種 PNM 技術作為未來形態(tài)的 PIM 計算架構加以提出����。
PIM技術路線圖
以 PNM 為核心形態(tài)的 PIM 架構,具備從加速器向獨立計算平臺演進的潛力�,并有望在未來的數(shù)據(jù)中心化(data-centric)計算體系中,成為支撐 AI 推理與訓練的重要基礎硬件形態(tài)����。PIM 的發(fā)展路徑可概括為兩個階段:到2034 年:PIM 主要作為 GPU 生態(tài)中的高性能組件存在����,重點加速推理類 GEMV 運算����,并逐步擴展至受限訓練場景;到2040 年:PIM 通過 PNM 架構實現(xiàn)規(guī)?���;ミB與協(xié)同計算����,逐步承擔核心計算角色,覆蓋推理與訓練任務���,形成以 PIM 為中心的計算體系���。
在結構上,該路線圖傾向于采用 DRAM + Base die(邏輯工藝) 的 PNM 形態(tài)�,通過 TSV 與先進封裝實現(xiàn)高帶寬互連,并在 Base die 中引入可擴展計算與片內 CIM����,以提升系統(tǒng)整體的 roofline 上限�。
PIM 技術的進一步發(fā)展仍面臨若干關鍵挑戰(zhàn):CIM–PIM 間的 TSV 高帶寬�、低功耗互連;Base die 與 DRAM die 的功能劃分與散熱管理�;與 Host-processor 軟件棧的協(xié)同與可編程性問題;PIM Cube 之間的低功耗���、超高速互連機制����。這些問題不僅涉及器件與封裝層面�,也直接關系到系統(tǒng)架構與軟件生態(tài)的接受程度。
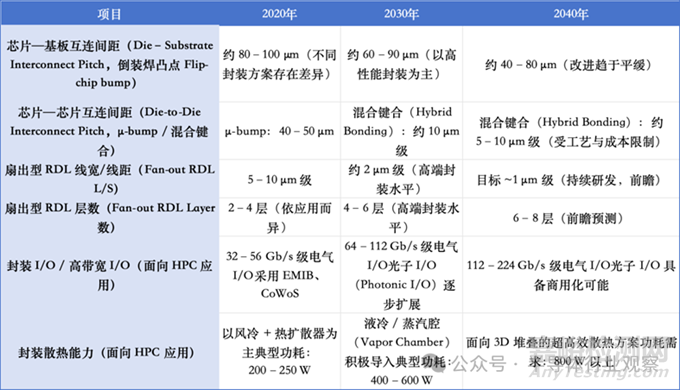
8���、半導體封裝技術
本路線圖將封裝技術劃分并定義為五個主要方向����。第一�,介紹將單一芯片封裝為一個整體的 Single-Chip 結構,以及將多個芯片集成為一個模塊的 Multi-Chip 結構����。第二,從封裝內部布線與互連的角度�,區(qū)分傳統(tǒng)的 2D 封裝�、采用高密度中介層或橋接結構的 2.xD 封裝�,以及垂直堆疊的 3D 封裝,并分別進行說明����。第三,討論在晶圓或面板層級同時完成多芯片封裝的扇出型晶圓級 / 面板級封裝(FO-WLP/PLP)技術���。第四�,針對 HPC 與數(shù)據(jù)中心封裝���,重點介紹構建高性能計算系統(tǒng)所需的核心封裝技術,包括基于 Chiplet 的異構集成����、超高帶寬存儲器(HBM)耦合、細間距互連與 Die-to-Die 標準�,以及應對高熱密度的封裝與散熱結構。第五����,涵蓋在高功率、高密度環(huán)境中不可或缺的熱管理結構���,以及支撐整體封裝設計的建模����、仿真與協(xié)同設計(Co-Design)技術。
先進封裝技術路線圖
基于 Single-Chip 的集成方式����,正因制程成本上升與大尺寸 die 良率受限而逐步顯現(xiàn)出結構性約束。在此背景下�,基于 chiplet 的 Multi-Chip Integration 作為新的系統(tǒng)集成方式不斷擴散。同時�,封裝架構正從傳統(tǒng)的 2D 結構向 2.xD 與 3D 結構演進����,中介層、Fan-out RDL 以及基于混合鍵合的互連微縮�,已成為實現(xiàn)高帶寬與低時延特性的關鍵技術要素。此外�,F(xiàn)an-out 與 PLP 工藝作為同時追求封裝微縮與生產(chǎn)效率提升的技術,其應用范圍也在逐步擴大�。
HPC與數(shù)據(jù)中心領域是最早、也是最強烈推動上述封裝技術變革的代表性應用場景����。在這些系統(tǒng)中�,基于 chiplet 的架構����、HBM 的集成、高密度互連���,以及電力與冷卻的一體化設計���,已成為決定系統(tǒng)性能與可擴展性的核心因素。同時���,隨著結構向高集成度與高功率密度發(fā)展����,熱管理����、多物理場建模以及基于 Co-Design 的綜合設計環(huán)境�,正被視為決定封裝性能與可靠性的必備基礎技術。
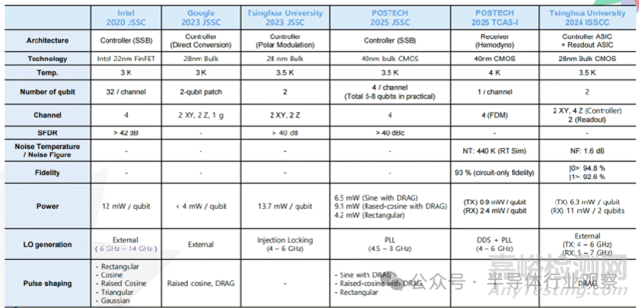
9���、量子計算半導體技術
量子計算通過對量子比特的量子力學現(xiàn)象進行控制�,以概率性、可逆的運算方式����,相較經(jīng)典計算機可實現(xiàn)更優(yōu)異的性能和計算速度����。在多種量子比特類型中,超導量子比特因其與半導體工藝的高度兼容性����、良好的集成性以及快速的門操作速度,在產(chǎn)業(yè)界和學術界得到了極為活躍的研究�。
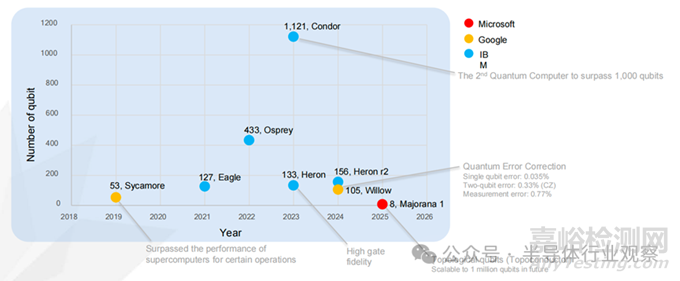
國際上 IBM�、Google、Intel����、Rigetti����、D-Wave 等重點布局超導量子比特;IonQ�、Quantinuum 深耕離子阱路線;Xanadu�、PsiQuantum 則專注光子量子計算。Google 已通過隨機量子電路實驗驗證量子優(yōu)越性����,Intel 與 QuTech 在低溫自旋量子比特方面取得階段性成果����。如下圖所示。
由于在工藝成熟度����、集成潛力與半導體兼容性方面具備顯著優(yōu)勢����,超導量子比特被普遍認為是最具現(xiàn)實可行性的量子計算實現(xiàn)路徑之一。近年來�,其核心指標——量子比特規(guī)模�、門操作保真度及糾錯能力——持續(xù)提升(見下圖)。從時間軸看�,Google 于 2019 年推出 53 比特 Sycamore;IBM 在 2021–2023 年間相繼發(fā)布 Eagle(127 比特)、Osprey(433 比特)與 Condor(1,121 比特)����;2024–2025 年,Heron�、Willow 及 Majorana 系列處理器在可靠性、糾錯率和新型拓撲架構方面取得突破�,標志著系統(tǒng)工程能力的顯著提升。
全球量子計算市場正快速增長�,量子計算被視為核心驅動力之一。主要企業(yè)已不再局限于硬件研發(fā)����,而是同步構建云端可訪問的量子計算服務與軟件生態(tài),如 IBM Quantum���、Azure Quantum 等����??傮w趨勢顯示,硬件—軟件—云平臺的一體化正在成為量子計算產(chǎn)業(yè)化的主線���。
綜合現(xiàn)有研究與產(chǎn)業(yè)規(guī)劃����,量子計算技術正沿著“驗證 → 集成 → 容錯 → 規(guī)模化”的路徑演進(見下圖)�。
2024–2025 年:中等規(guī)模量子處理器實現(xiàn)穩(wěn)定運行,Cryo-CMOS 控制與低溫讀出逐步集成�。
2026–2028 年:數(shù)千量子比特級模塊化架構出現(xiàn),自動化糾錯機制確立���。
2029–2035 年:容錯量子計算機與邏輯量子比特規(guī)?��;涞兀孔觾?yōu)勢在材料���、化學等領域得到驗證���。
2036–2040 年:量子計算與 HPC、AI 深度融合���,形成以 QPU 為核心的量子中心計算平臺�。
10����、結語
縱觀這份長達百余頁、跨越15年的路線圖����,我們看到的不僅是一系列令人驚嘆的技術參數(shù),更是半導體產(chǎn)業(yè)在面對物理極限時的一次集體“突圍”�。ISE所描繪的未來,是一個“邊界消失”的世界:邏輯與存儲通過3D混合鍵合融為一體����,光信號在芯片內部取代銅線穿梭,傳感器從單純的數(shù)據(jù)采集器進化為擁有自主意識的探測節(jié)點����,而量子比特則在極低溫的寂靜中重塑計算的本質。這反映了半導體產(chǎn)業(yè)最深層����、也最具觀察力的轉折——單一技術的紅利已經(jīng)枯竭,全棧式的系統(tǒng)集成正成為新的主權邊界����。在這場通往2040年的長跑中,0.2nm或許是工藝的終局���,但對于真正決定計算未來的系統(tǒng)性重構而言����,大幕才剛剛開啟。